
Token Budget Negotiator: Greedy Ablation Prompt Compression with Quality Gating
The Problem
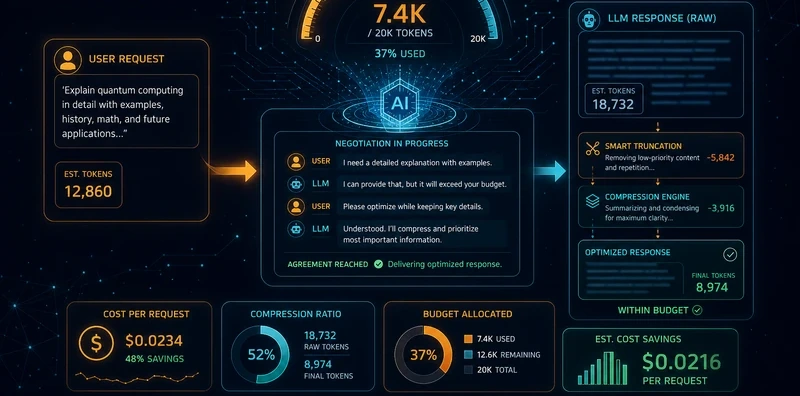
You have a prompt that costs 4,000 tokens. Some sections are essential, the task definition, the constraints, the examples. Others are redundant, context you added months ago for a use case that no longer applies, verbose instructions that could be a sentence, boilerplate you copied from a template. You know it could be shorter. You don't know which parts to cut, and you don't want to spend an afternoon running ablations by hand.
NEO built Token Budget Negotiator to run those ablations automatically, with a quality floor that stops it from cutting things that actually matter.
Greedy Ablation Strategy
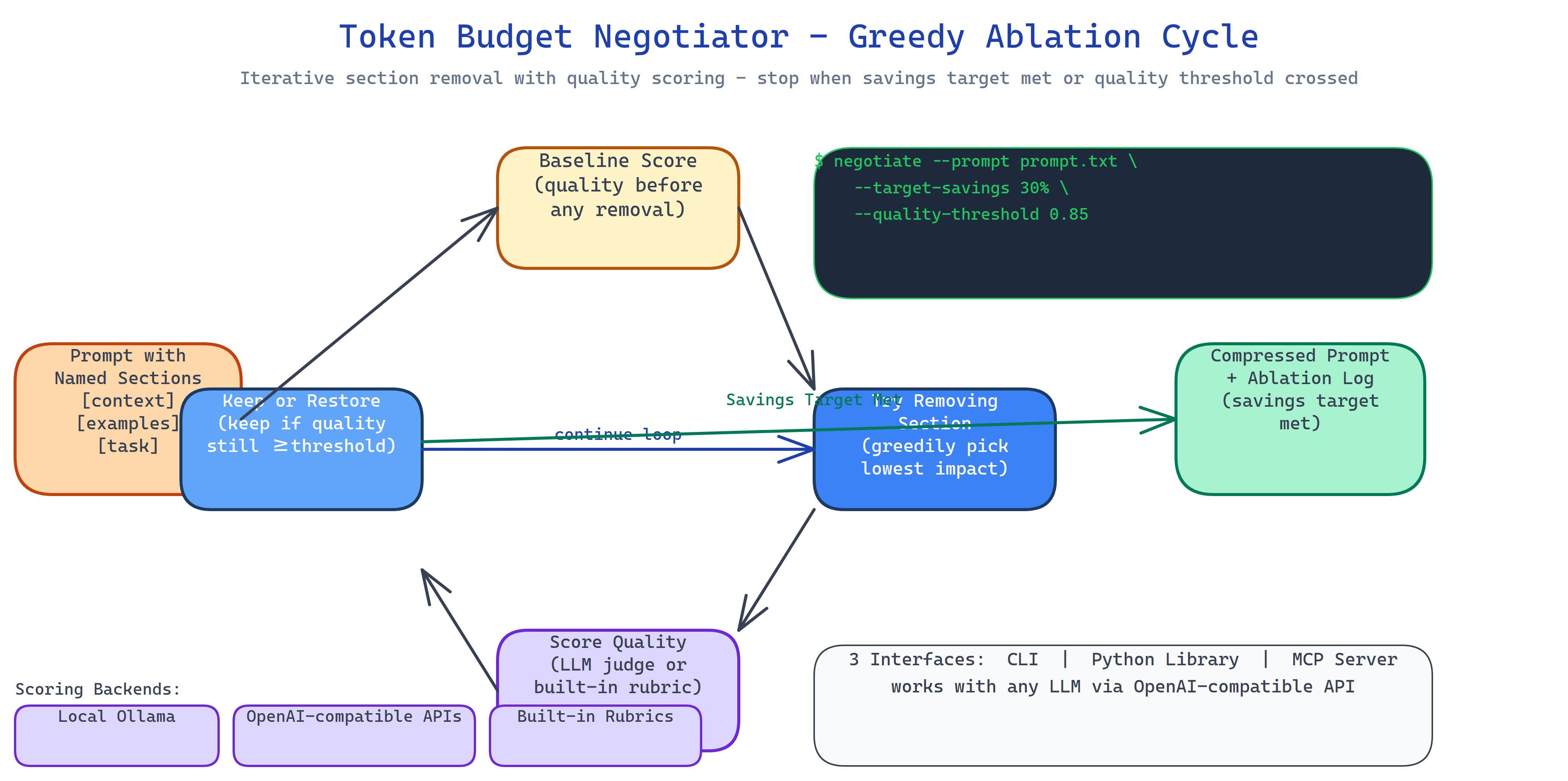
The negotiator splits your prompt into named sections and tests removing each one:
- Baseline: score the complete prompt using your chosen scoring backend (Ollama or OpenRouter).
- Ablate: try removing each section in order of estimated priority.
- Score: check if quality stays above your threshold after removal.
- Decide: if quality holds, the section stays removed. If quality drops below threshold, it gets restored.
- Stop: halt when token savings reach your minimum target, or when removing any remaining section would breach the quality floor.
The result is the shortest prompt that passes your quality bar, with a log of every ablation decision.
Three Scoring Backends
Quality is measured by the scoring backend you configure:
- Local Ollama: no API cost, runs offline, uses whichever model you have pulled.
- OpenAI-compatible APIs: OpenRouter, Together, any endpoint with the OpenAI SDK.
- Built-in rubrics: the tool ships rubrics for QA, coding, and summarization tasks so you can score without running a second model for simple use cases.
Token counting uses tiktoken for GPT-family models with fallback estimation for others.
Three Interfaces
CLI: point it at a prompt file, set your targets, get back the compressed prompt and an ablation log:
negotiate --prompt system_prompt.txt --target-savings 30% --quality-threshold 0.85
negotiate --prompt prompt.txt --backend ollama --model llama3.2:3b
Python library: integrate into your prompt management pipeline:
from token_budget_negotiator import Negotiator
n = Negotiator(backend="openrouter", quality_threshold=0.85, target_savings=0.30)
result = n.negotiate(prompt)
print(result.compressed_prompt, result.savings_pct, result.ablation_log)
MCP server: expose the negotiator as a tool to Claude Code and other agents. The agent calls negotiate_prompt with the prompt text and gets back the compressed version with savings metadata.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a prompt compression tool that uses greedy ablation to remove sections that don't meaningfully impact quality. Split prompts into named sections, score the full prompt as a baseline, then iteratively try removing each section and rescoring, restoring sections where quality drops below a threshold, keeping removals where it holds. Stop when token savings reach the minimum target. Support Ollama and OpenAI-compatible APIs as scoring backends. Count tokens via tiktoken with fallback estimation. Ship three interfaces: a CLI tool, a Python library, and an MCP server. Include built-in rubrics for QA, coding, and summarization scoring tasks. Add caching and verbose logging."
NEO scaffolds the section parser, the greedy ablation loop, the quality gating logic, the three scoring backends, the tiktoken integration, and all three interfaces. From there you iterate: add a budget cap that stops compression once you hit a target token count rather than a percentage, add a second-pass optimizer that tries recombining retained sections for further savings, or pipe the MCP tool into a CI job that automatically audits new prompts before they ship.
To run the finished project:
git clone https://github.com/dakshjain-1616/Token-Budget-Negotiator
cd Token-Budget-Negotiator
pip install -r requirements.txt
negotiate --prompt my_prompt.txt --target-savings 30% --quality-threshold 0.85
negotiate --prompt my_prompt.txt --backend ollama --model llama3.2:3b
negotiate --prompt my_prompt.txt --verbose # see every ablation decision
NEO built a greedy ablation prompt compressor with quality gating, three scoring backends, and CLI/library/MCP interfaces, so shrinking overlong prompts is a one-command operation with a quality floor. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor