
Synthetic Data Generation Is Easy. Dataset Engineering Is Hard.

The Problem
Five hundred synthetic software-incident records sounds modest until you list what "production-ready" actually means:
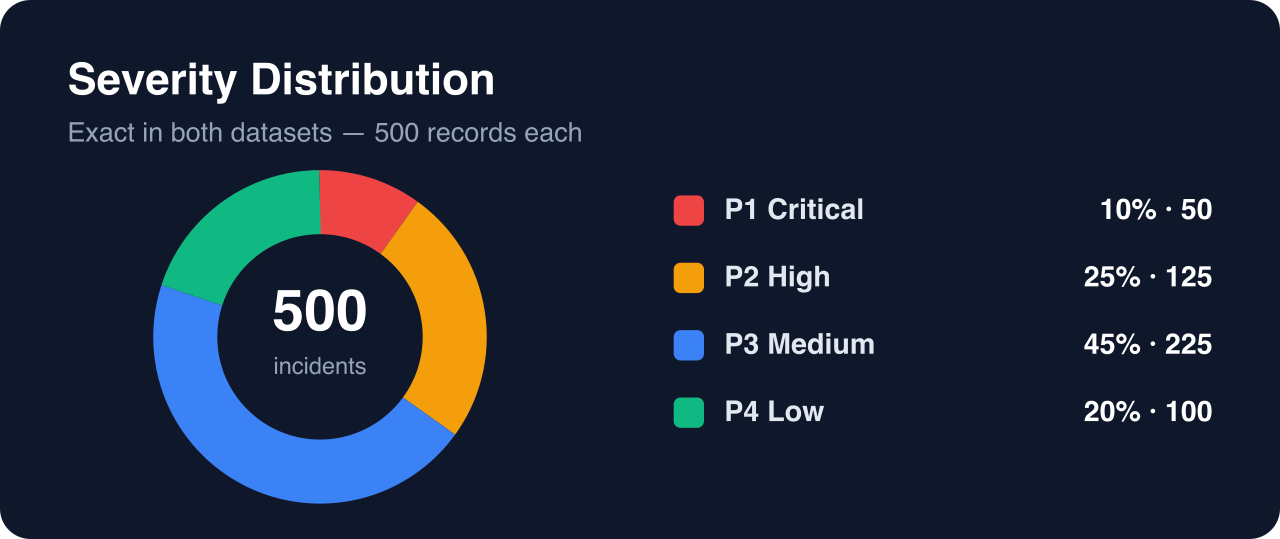
- Exact severity quotas (P1=10%, P2=25%, P3=45%, P4=20%)
- Chronologically valid timelines from detection through postmortem
- No hidden duplicate archetypes dressed up as unique incidents
- Nested fields that validate, not just top-level JSON that parses
- An audit trail a release manager can sign off on
Templates and randomizers can fill rows quickly. Dataset engineering is what keeps those rows trustworthy when the file lands in SRE training, agent eval, or a version-controlled benchmark.
Synthetic data generation is easy. Dataset engineering is hard. That is the gap Neo MCP closes.
The Solution
Neo MCP adds a validation and refinement layer on top of generation. Claude Code still drives orchestration. Neo MCP compiles the output into an audit-ready incident-replay dataset with deterministic defect management, nested-field checks, and reproducible remediation steps documented in the artifact set.
The Benchmark Task
Both workflows targeted the same deliverable:
- 500 high-fidelity synthetic incident-replay records
- 10 categories, 50 records each
- Exact P1/P2/P3/P4 severity distribution
- 100% top-level schema compliance
- Weighted evaluation across realism, structure, and operational usefulness
Starting Point
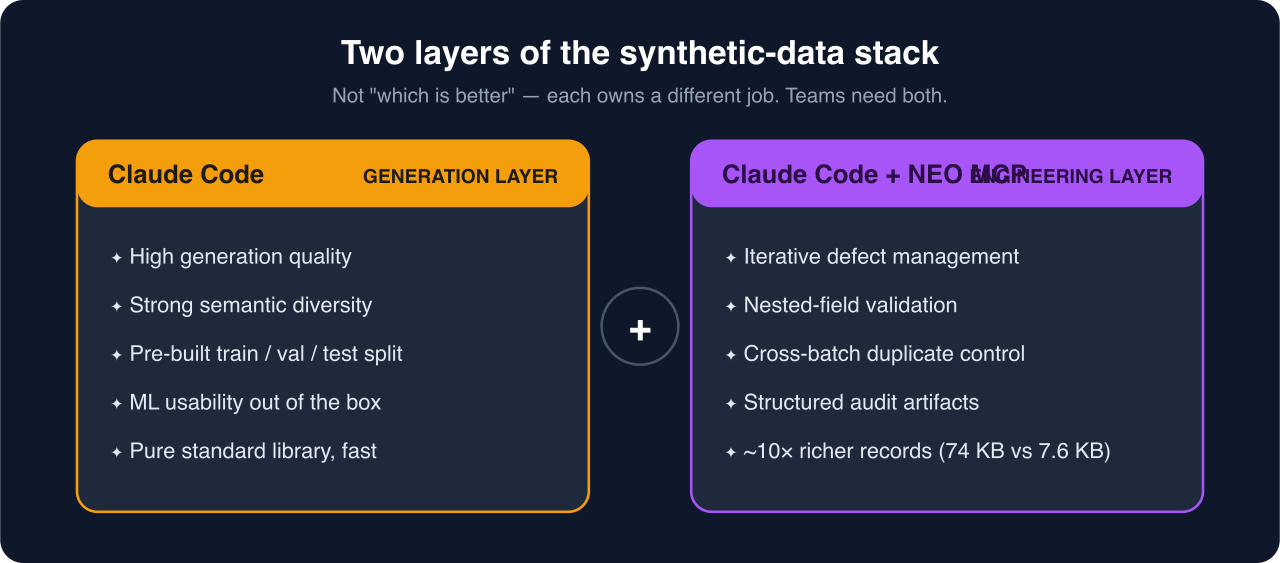
The first pass produced 500 compliant records with strong narrative variety and ML-friendly train/val/test splits. It also surfaced classic dataset-engineering debt: duplicate title archetypes, incomplete lifecycle phases, and severity sampling that approximated targets without hitting them exactly.
Dataset Generation vs. Dataset Engineering
Generation optimizes individual records: plausible logs, believable metrics, readable narratives.
Engineering optimizes the pipeline: exact quotas, dedup at generation time, nested validation, defect tracking, and artifacts that prove fixes landed across all 500 rows.
At small scale you can eyeball records. At benchmark scale you need the second layer.
Generation optimizes records. Engineering optimizes the pipeline you can re-audit, version, and ship with evidence.
What Neo MCP Changed
Neo MCP introduced five concrete engineering upgrades, each with full coverage across the shipped dataset:
Exact severity distribution
Probabilistic sampling was replaced with exact count lists per 50-record batch. Final distribution: P1=50 (10%), P2=125 (25%), P3=225 (45%), P4=100 (20%).
Eleven-phase incident timelines
Lifecycle coverage expanded from eight phases to eleven, including postmortem and validation stages required for causal reasoning evals.
Generation-time deduplication
Duplicate detection now includes severity in the fingerprint. Title/archetype collisions that passed a shallow audit were eliminated at generation time.
Mechanistic root-cause descriptions
100 failure-mode × category combinations received specific mechanism strings instead of circular category self-references.
Nested-field validation
Enum checks, timeline ordering rules, and cross-field consistency gates run as part of the engineering loop, not as a post-ship surprise.


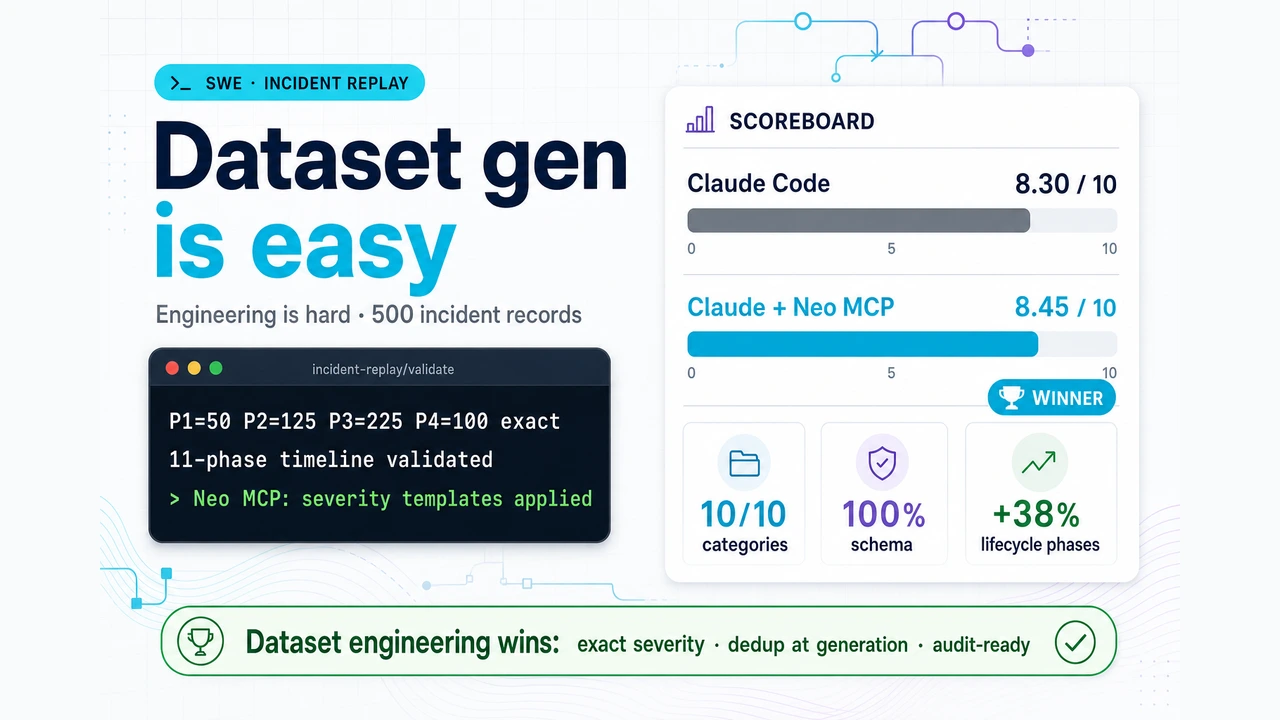
Results
Both pipelines delivered 500 records that met the published contract. Weighted evaluation scores were 8.30 (starting workflow) and 8.45 (Claude Code + Neo MCP). The scores are close because both satisfied the headline requirements. The engineering gap shows up in how the dataset stays correct:
| Metric | Outcome with Neo MCP |
|---|---|
| Severity quotas | Exact P1–P4 counts |
| Schema compliance | 100% top-level + nested validation |
| Lifecycle phases | 11 phases, +38% coverage vs baseline |
| Title/severity consistency | 0 urgency mismatches across 500 records |
| Circular root causes | 0 self-referential strings |
| Defect remediation | Documented Generator v2.0 fixes, independently verified |
Neo MCP's value is not a dramatic score bump on day one. It is headroom: the dataset is easier to re-audit, version, and extend without silent drift.
Neo MCP turns a successful generation sprint into a dataset you can trust in a production pipeline, not a one-off export you hope still holds next quarter.
Key Lessons for Dataset Engineers
- Treat synthetic data as infrastructure, not a one-off export.
- Move dedup and quota enforcement into generation, where fixes are deterministic.
- Ship audits that count nested fields, not just top-level keys.
- Document remediation so the next engineer knows which defects were explicitly closed.
Practical Implications
- SRE training programs get timelines that support causal drills, not just alert text.
- Benchmark owners can enforce exact severity mixes required by eval contracts.
- Platform teams inherit versioned methodology plus independent audit reports suitable for release review.
Conclusion
Synthetic incident replay is a generation problem at small scale and an engineering problem at production scale. Neo MCP is the layer that turns a successful generation sprint into a dataset you can trust in a pipeline: exact quotas, expanded lifecycles, generation-time dedup, and audit evidence that survives the next release.
Neo MCP is how you graduate from "we generated 500 incidents once" to "we operate an incident-replay dataset program."
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor