

From Dataset Generation to Dataset Engineering: What Changed When We Added Neo MCP
The Problem
Synthetic agent failure datasets are easy to start and hard to trust.
A thousand JSONL rows with the right field names can look complete on first inspection. The real risk shows up later: duplicate fingerprints that slip through post-hoc dedup, audit reports that cannot gate a CI job, and pipelines that produce different files on every rerun. Teams building evaluation harnesses do not just need records. They need dataset engineering: reproducibility, validation, auditability, and traceability from spec to shipped artifact.
That is the gap this benchmark targeted.
Teams do not just need records. They need dataset engineering: reproducibility, validation, auditability, and traceability from spec to shipped artifact.
The Benchmark Task
We asked two automated workflows to produce the same contractual dataset:
- 1,000 records of synthetic AI agent failures
- 10 failure categories with balanced severity and difficulty
- 15-field JSONL schema with full audit coverage
- Evidence artifacts a reviewer can replay without manual inspection
Claude Code orchestrated both runs. The difference was whether Neo MCP sat in the loop as a deterministic engineering layer on top of generation.
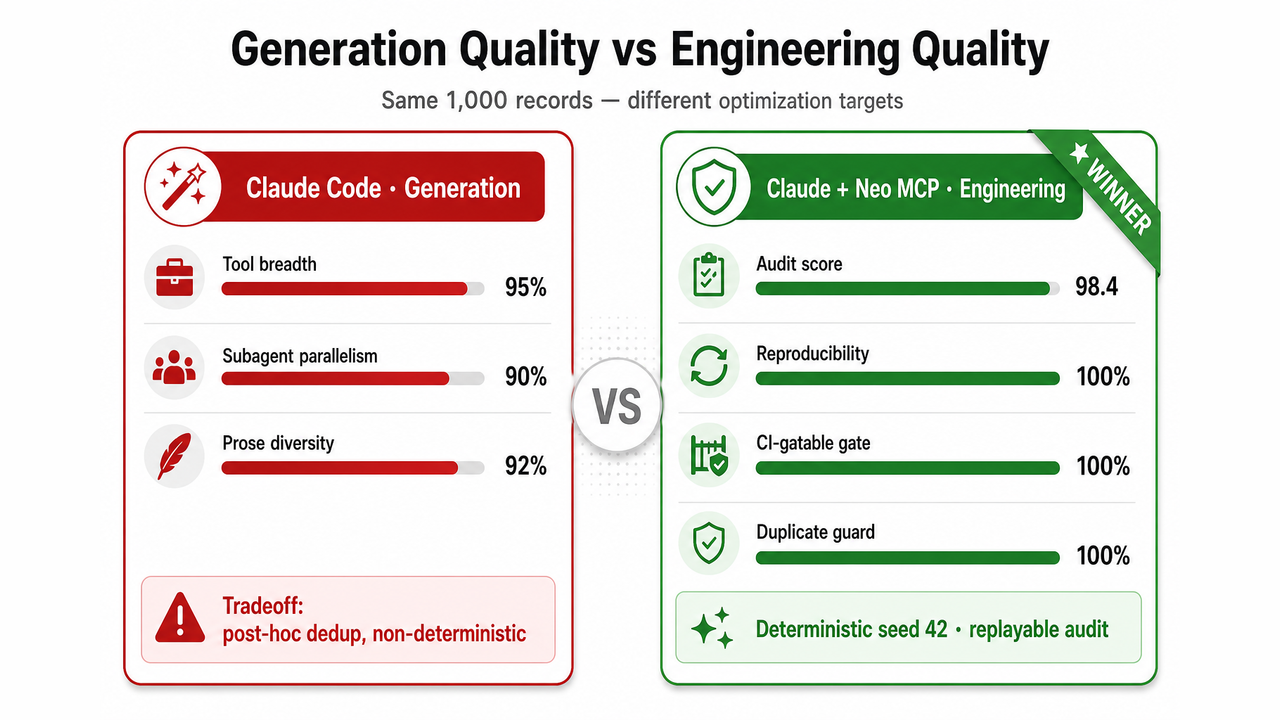
Starting Point
The first workflow used Claude Code as a multi-subagent orchestrator: publish a spec, fan out parallel authors, merge batches, and run validation after the fact. It delivered a rich dataset and met the contract. What it did not deliver was a replayable pipeline you could pin in CI, rerun on demand, and gate on a machine-readable audit score.
What Neo MCP Changed
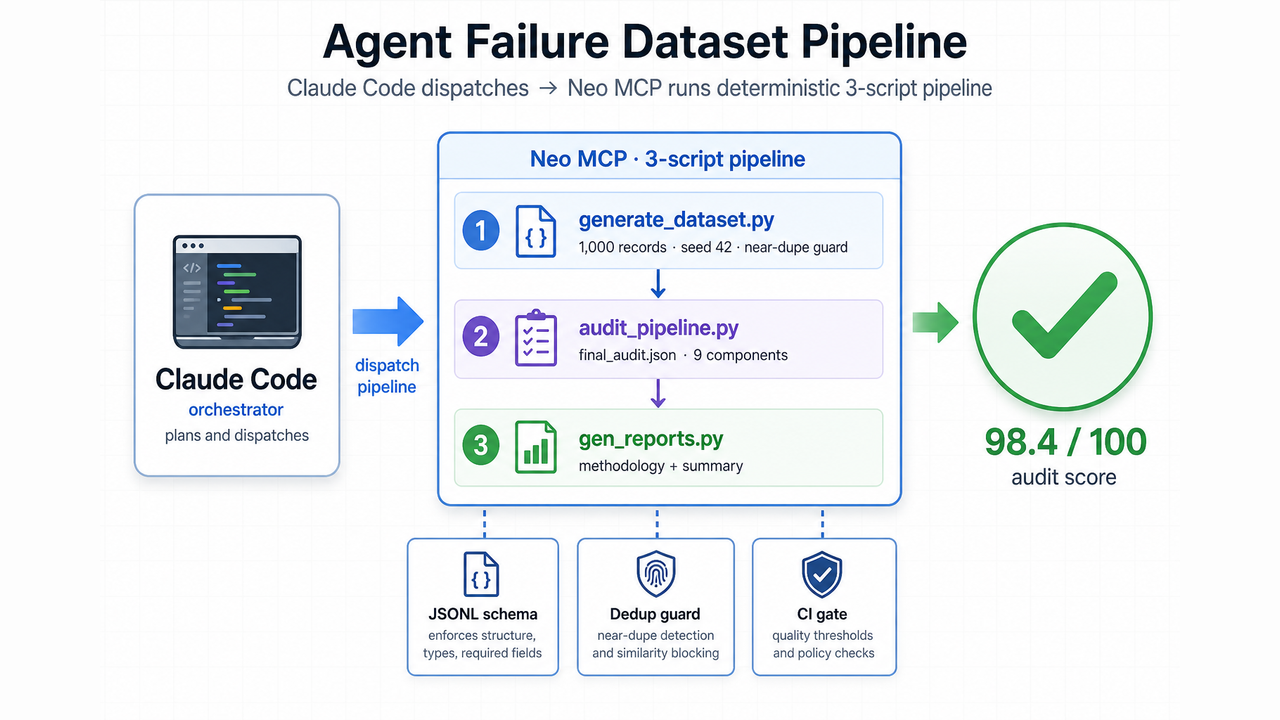
Neo MCP reframed the job from "generate 1,000 rows" to "operate a three-script dataset pipeline with a published plan, deterministic seeds, and a final audit gate."
Neo MCP shifts the question from "did we hit 1,000 rows?" to "can we rerun, re-audit, and gate this in CI on every release?"
Deterministic reproducibility
Generation seeds at 42. Parameterized template filling reproduces the same dataset and metrics byte-for-byte on rerun. Methodology documents the seed contract explicitly so reviewers can verify claims without trusting a one-off export.
Generation-time duplicate guard
Near-duplicate rejection happens during generate_dataset.py, not in a cleanup pass after merge. That shifts dedup from a forensic exercise into a pipeline invariant.
CI-gatable audit infrastructure
audit_pipeline.py emits final_audit.json with nine scored components. The composite lands at 98.4 / 100, high enough to treat as a release gate rather than a narrative footnote.
Three-script modular pipeline
| Script | Role |
|---|---|
generate_dataset.py | Build 1,000 records with seed-42 guards |
audit_pipeline.py | Score schema, balance, and quality components |
gen_reports.py | Publish methodology and dataset summary artifacts |
Planning lives in versioned docs. Execution is script-bound. Reviewers read JSON, not chat logs.
Results
Both workflows met the published contract. The engineering distinction shows up in how you operate the dataset afterward:
| Dimension | Neo MCP outcome |
|---|---|
| Reproducibility | Seed-42 replay documented in methodology |
| Audit gate | final_audit.json, 98.4 / 100 composite |
| Dedup | Generation-time guard in generate_dataset.py |
| Operability | Three-script pipeline suitable for CI wiring |
| Traceability | Plan + audit + summary artifacts shipped together |
The headline is not "more prose per record." It is a dataset you can version, re-audit, and ship with evidence.
Neo MCP is built for the second phase: turning a successful generation sprint into a maintainable dataset operation.
Lessons for Dataset Engineers
Generation quality and engineering quality are different optimization targets. Volume and variety matter for exploration. Reproducibility, audit gates, and modular pipelines matter when a dataset becomes infrastructure.
If your team is moving from one-off synthetic exports to governed evaluation data, invest in:
- Deterministic seeds and documented rerun contracts
- Machine-readable audits that CI can fail on
- Duplicate guards at generation time, not merge time
- Script-bound pipelines with explicit planning artifacts
Neo MCP is built for that second phase: turning a successful generation sprint into a maintainable dataset operation.
Practical Implications
- Platform teams can wire
final_audit.jsoninto release checks the same way they wire unit tests. - Eval owners get a rerun story when stakeholders ask "prove this still holds."
- Data engineers inherit a three-script surface area instead of a one-off merge notebook.
Conclusion
Adding Neo MCP did not change the contract. It changed the class of system producing the dataset: from orchestrated generation to an engineered, auditable pipeline. For teams scaling synthetic eval data, that is the difference between a demo export and a dataset you can run in production.
Neo MCP is how you graduate from "we generated a dataset once" to "we operate a dataset program."
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor