

Managed Synthetic Data: What Happens When Dataset Pipelines Start Governing Themselves
An engineering case study in feedback loops, remediation infrastructure, and governed synthetic data operations.
The Problem
Seven hundred fifty valid JSON examples is a solved generation problem. A template, a seed, and a serializer get you there in one pass.
The unsolved problem is governance across iterations:
- Schema validity on every field, not just happy-path samples
- Exact category and difficulty balance after multiple regeneration passes
- Duplicate-free output you can prove from raw data
- A remediation story when an audit finds gaps
Teams running agent eval programs hit this wall the moment a dataset becomes a recurring release artifact, not a one-time export.
Generation creates examples. Governance creates trustworthy datasets. That is the job Neo MCP automates.
The Benchmark Task
We benchmarked two automated pipelines against the same contract:
- 750 synthetic agent evaluation examples
- 10 categories, 75 examples each
- Exact 30 / 50 / 20 easy / medium / hard difficulty split
- 47 / 47 tool-palette utilization requirement
- Independent audit evidence shippable with the dataset
Claude Code orchestrated both runs. Neo MCP added a governed loop with detect → remediate → verify infrastructure.
Starting Point
The baseline workflow optimized for a clean first pass: author templates, expand per category, emit validated batches, merge, and publish audit reports. It met every mandatory requirement in a single generation cycle. What it did not build was machinery to self-correct when a later audit finds drift, gaps, or balance errors.
From Dataset Generation to Dataset Management
Generation answers: "Can we produce valid rows?"
Management answers: "Can we keep the dataset valid as requirements evolve, and prove it after each change?"
Management answers: "Can we keep the dataset valid as requirements evolve, and prove it after each change?"
Neo MCP treats the dataset as a managed asset with planning artifacts, remediation scripts, and replayable verification, not a one-shot export.
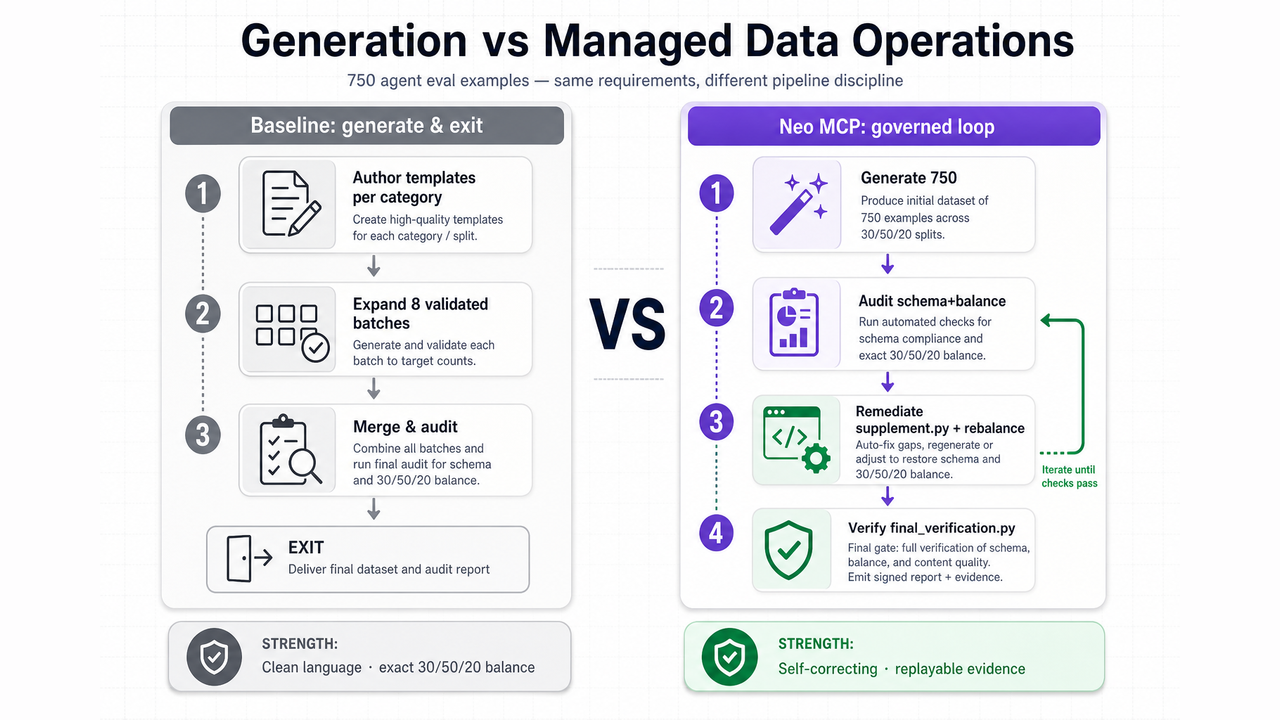
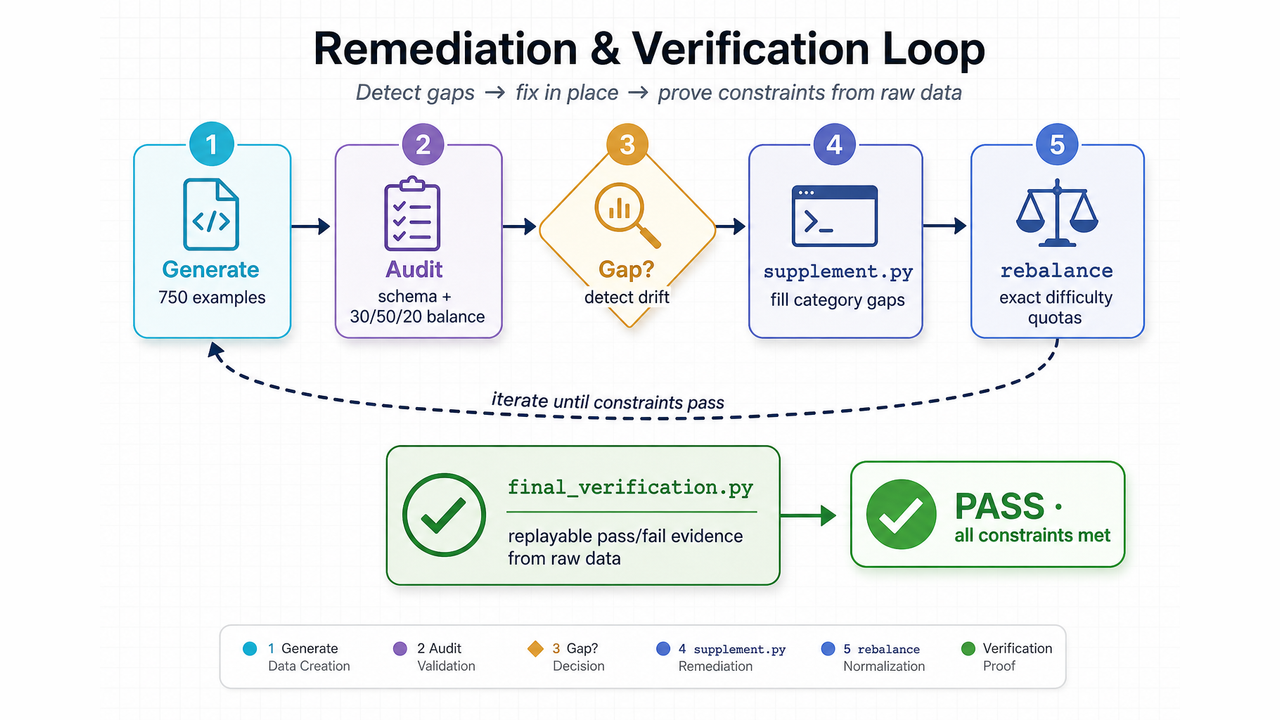
What Neo MCP Changed
Neo MCP introduced six workflow capabilities that turn one-shot generation into managed synthetic data operations:
1. Governed generate → audit → remediate loop
Generation is the first step, not the last. Audits feed supplement.py and rebalance_difficulty.py until constraints pass.
2. Replayable verification
final_verification.py recomputes pass/fail from raw records so reviewers do not rely on narrative claims.
3. Planning traceability
plans/plan.md documents intent, constraints, and remediation history across iterations.
4. Coverage management
Category and difficulty targets are checked after each pass, not assumed from the initial template.
5. Batch-level validation discipline
Eight validated shards merge into a governed whole with per-batch audit hooks.
6. Before/after reporting
Remediation runs ship evidence of what changed and why, suitable for platform review.
Quantitative Results
Both pipelines satisfied the mandatory contract. The structural difference is operational:
| Capability | Neo MCP outcome |
|---|---|
| Schema validity | 100% on shipped records |
| Category balance | 75 per category, verified |
| Difficulty split | Exact 30/50/20 after remediation |
| Tool palette | 47/47 tools represented |
| Verification | Replayable final_verification.py evidence |
| Remediation | supplement.py + rebalance_difficulty.py in loop |
Neo MCP optimizes for datasets you can re-certify on demand, not just datasets that look correct on first inspection.
Neo MCP is how you graduate from "we generated 750 examples once" to "we operate a governed eval dataset program."
Lessons for Dataset Engineering Teams
- One-shot generation is a prototype stage, not the finish line for eval infrastructure.
- Remediation scripts belong in the repo, next to generators, with the same review bar.
- Verification must replay from raw data so audits survive personnel turnover.
- Planning artifacts are part of the dataset product, not meeting notes.
Practical Recommendations
- Wire
final_verification.pyinto CI for any synthetic eval set that ships more than once. - Treat difficulty and category balance as constraints with automated repair, not spreadsheet checks.
- Keep
plans/plan.mdversioned alongside JSONL so reviewers see intent and deltas together. - Prefer governed loops when stakeholders ask "how do we know this still holds next quarter?"
Conclusion
Generation creates examples. Governance creates trustworthy datasets.
For AI platform teams shipping agent evals as a product, Neo MCP is the difference between a demo dataset and managed synthetic data operations.
Neo MCP showed what happens when synthetic data pipelines start managing themselves: feedback loops, remediation infrastructure, and verification you can run again without re-explaining the benchmark.
What This Means for AI Platform Teams
Platform owners inherit three durable wins:
- Lower review friction: verification scripts replace ad-hoc spot checks.
- Safer iteration: remediation loops absorb requirement changes without manual rescues.
- Clear ownership: planning and audit artifacts make dataset releases legible to infra and eval teams alike.
Neo MCP is how you graduate from "we generated a dataset once" to "we operate a dataset program."
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor