
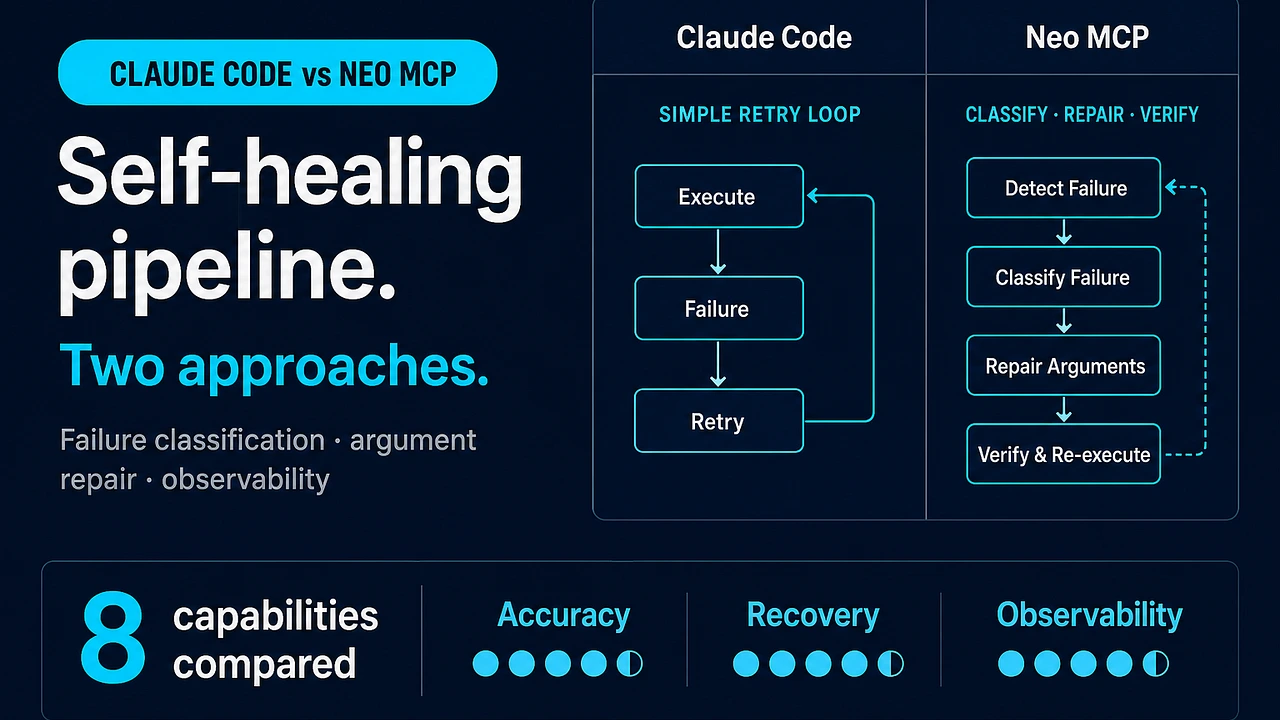
Building a Self-Healing AI Pipeline: Claude Code vs Claude Code + Neo MCP
The Question
Most AI coding assistants can generate code.
The more interesting question is:
Can they improve how AI systems are engineered?
To test this, we asked both systems to build a production-grade self-healing AI pipeline capable of:
- Detecting failures
- Diagnosing root causes
- Recovering autonomously
- Maintaining observability
- Supporting production deployment
The Benchmark Task
Both implementations were asked to solve the same compound goal against a deliberately flaky tool environment:
Search for customer data, calculate the average lifetime value from the database, and write the output file.
The mock toolchain includes three tools: WebSearch, DatabaseQuery, and SecureWrite. DatabaseQuery fails roughly half the time with transient JSONDecodeError or RateLimitException responses. That setup forces the agent to survive real-world failure modes, not just happy-path demos.
We compared two builds from the same starting brief:
| Implementation | How it was built | Entry point |
|---|---|---|
claudecode/ | Claude Code only (ReflectiveAgent) | python3 run.py |
neo-mcp/ | Claude Code + Neo MCP (SelfHealingAgent) | python3 main.py |
Both run offline with zero runtime dependencies on the deterministic path (Python 3.10+). Set ANTHROPIC_API_KEY and either agent transparently switches to a real claude-opus-4-8 planner with no code changes.
What We Expected
We expected both systems to generate:
- Retry logic
- Error handling
- Monitoring code
And they did.
The surprising difference was not in the code itself.
It was in the engineering workflow.
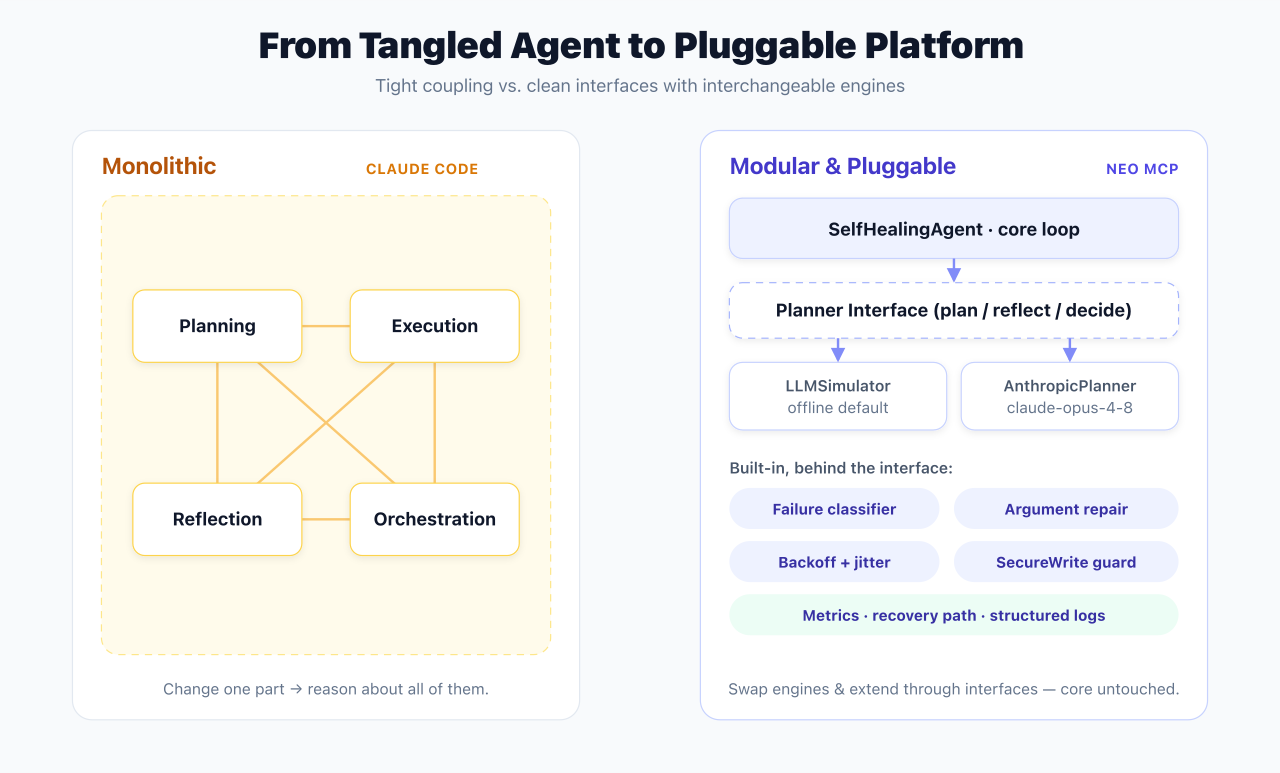
What Claude Code Built
Claude generated a working self-healing agent: a pure-Python ReflectiveAgent with a bounded retry loop, reflective exception handlers, and recovery metrics.
The implementation included:
- Planning and execution via
reasoner.py(offline deterministic reasoner, orAnthropicReasonerwhen an API key is present) - Two interchangeable planners (offline + Anthropic), swapped by shared method signature rather than a formal interface ABC
- Three mock tools in
tools.pywith a deliberate exception taxonomy - Reflection on failure: full stack traces appended back into context as
[TOOL_ERROR]system messages - Retry-vs-repair classification (
RateLimitException/JSONDecodeError→ transient;ToolInputError→ repair arguments) - Exponential backoff with auditable wait-time metrics
- A failure-heavy test harness in
run.pythat runs two resilience scenarios end to end
The result was functional and solved the task. Both scenarios in the harness end with the output file on disk (average_lifetime_value = 8200.0 over 5 customers) and OVERALL: PASS.
However, most of the system was organized around a single implementation path. The planning logic, recovery logic, and orchestration logic live in one agent class. As the system grows, modifying one area requires understanding multiple parts of the implementation.
How the Claude Code loop works
Each logical step (search → aggregate → write) runs up to max_retries attempts (default 3). On any exception:
- Capture the stack trace via
traceback.format_exc() - Append it to message history as a reflection signal
- Inject a
[SELF_CORRECTION]prompt for the reasoner - Classify transient vs deterministic failure and either back off or repair arguments
- Retry under the budget, or halt cleanly (
gave_up_stepsincrements) instead of crashing
A representative recovery metrics block from a full run:
"failures": 2, "failures_by_type": {"RateLimitException": 2},
"recoveries": 1, "retries": 2, "backoff_seconds": 0.3
What Changed With Neo MCP
Neo MCP shifted the problem from:
"Build a self-healing agent"
to
"Build a self-healing platform."
Instead of focusing solely on task completion, the generated architecture emphasized:
- Separation of concerns across planner, agent, tools, and exceptions modules
- Formal
PlannerInterfaceABC for planner swapping (both implementations ship two planners; Neo's edge is the explicit contract) - Structured recovery workflows with explicit classify → repair → verify stages
- Failure classification via
decide_next_actionwith five named actions: retry, modify, switch, abort, proceed - Recovery observability: both emit a metrics dict; Neo also records
recovery_path - Testable interfaces with a pytest suite and multi-seed harness (seeds 1–10, with seed 7 codified to produce
status == "partial")
This fundamentally changed the development experience.
Neo MCP architecture
planner_interface.py ← ABC: plan_goal / reflect / decide_next_action
├── llm_sim.py ← LLMSimulator (offline, deterministic)
└── anthropic_planner.py ← AnthropicPlanner (real LLM via API)
agent.py ← SelfHealingAgent with retry, repair, metrics
tools.py ← WebSearch, DatabaseQuery (flaky), SecureWrite
exceptions.py ← RateLimitException, ToolExecutionError
main.py ← Entry point with both demo scenarios
The self-healing flow is explicit:
- Plan: decompose the goal into ordered tool-call steps
- Execute: attempt each step; transient failures trigger jittered exponential backoff
- Reflect: append a reflection message to context on failure
- Classify:
decide_next_actionpicks one of five named recovery actions - Repair:
_repair_argsfixes bad arguments (e.g. unknown column → known-good column) without backoff - Metrics: record every failure, retry, backoff second, and recovery step in
recovery_path
Workflow Transformation
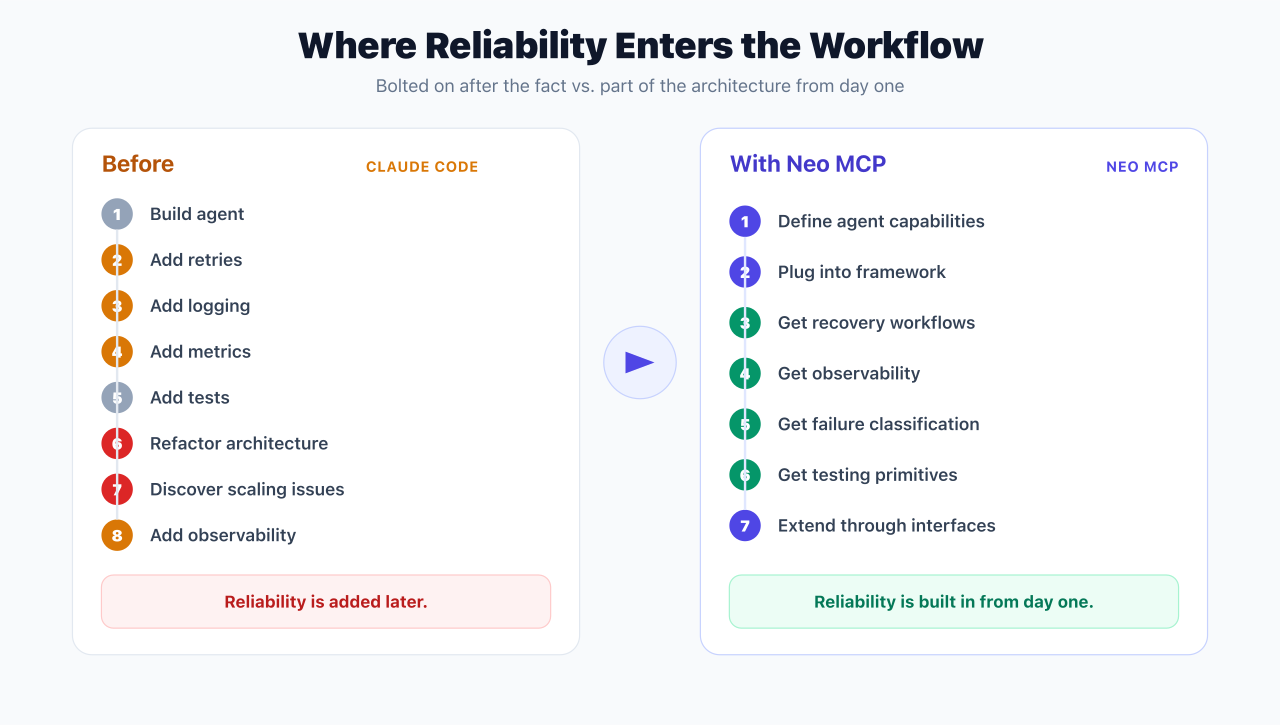
Before
Typical engineering workflow:
- Build agent
- Add retries
- Add logging
- Add metrics
- Add tests
- Refactor architecture
- Discover scaling issues
- Add observability
Reliability becomes something added later.
With Neo MCP
Typical workflow:
- Define agent capabilities
- Plug into framework
- Get recovery workflows
- Get observability
- Get failure classification
- Get testing primitives
- Extend through interfaces
Reliability becomes part of the architecture from day one.
The Most Interesting Difference
Claude treated self-healing as:
Recover when something breaks.
Neo MCP treated self-healing as:
Understand why something broke, classify the failure, choose a recovery strategy, verify the outcome, and record the incident.
That difference sounds subtle.
In production systems it is enormous, but both implementations recover. The gap is in how many named recovery actions exist and how explicitly each step is recorded.
Example: Tool Failure
Claude Approach
Tool fails
→ Classify (transient vs deterministic)
→ Backoff and retry (transient)
→ Reflect and repair args (deterministic)
→ Escalate if budget exhausted
Neo MCP Approach
Tool fails
→ Classify failure (decide_next_action)
→ Determine if transient
→ Repair arguments if possible (_repair_args)
→ Retry with jittered backoff
→ Verify output
→ Record recovery path
→ Escalate if required
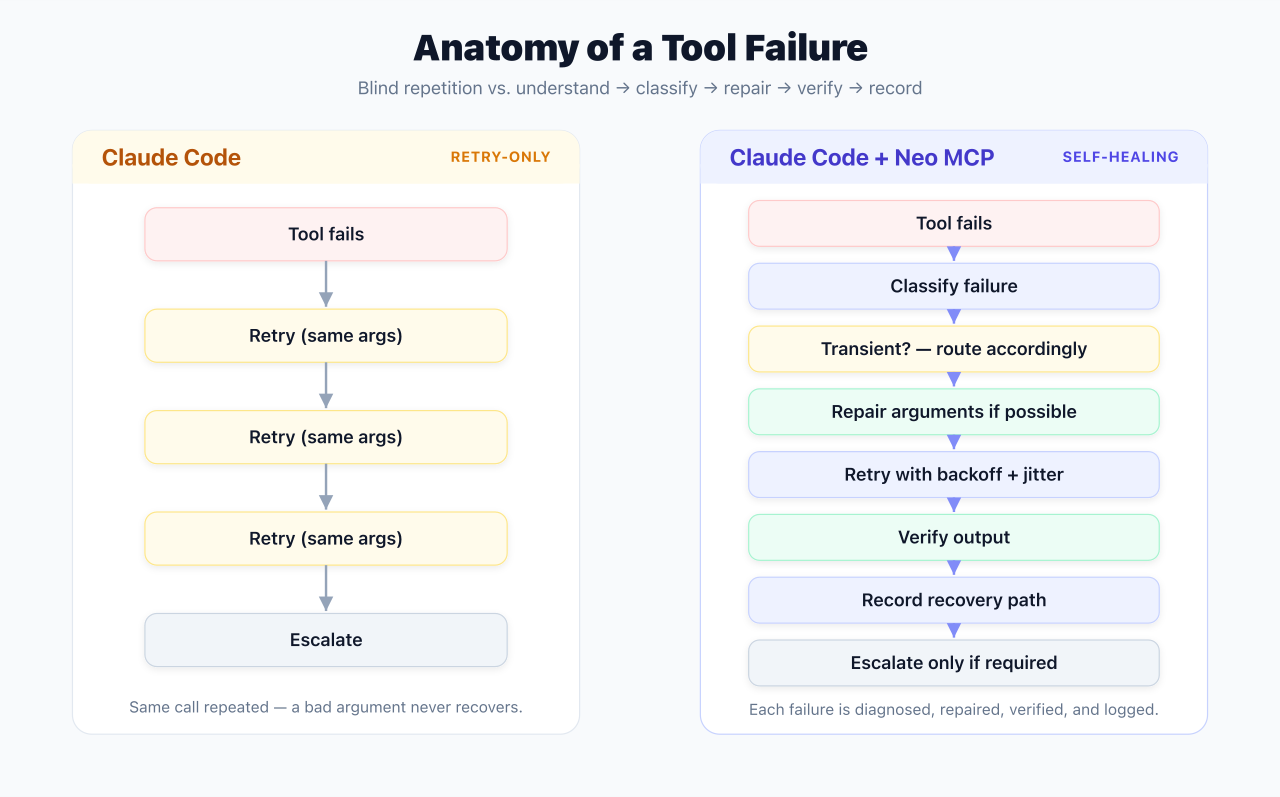
Neo MCP's advantage here is breadth: five named recovery actions, a dedicated repair function, jitter on backoff, and a recorded recovery_path. Claude Code already classifies and repairs (Scenario B proves it), but the logic is embedded in the reasoner loop rather than split into named steps.
What the test run proves
The harness exercises two failure modes that show up constantly in production agents:
Scenario A (flaky environment): DatabaseQuery throws transient rate-limit and JSON decode errors. The Claude Code agent backs off (0.1s → 0.2s) and recovers, then writes ltv_report.json. The Neo MCP agent classifies each failure, applies jittered backoff on transients, and verifies the write succeeded.
Scenario B (hallucination repair): both implementations recover. The planner's first database call uses plausible-but-wrong arguments (operation='average', no customer IDs). Claude Code's reasoner mutates the arguments implicitly from the injected stack trace and recovers on attempt 2. Neo MCP's _repair_args applies explicit column remapping and recovers the same way, writing ltv_report_b.json.
Both implementations pass. The difference is what you inherit when you extend the system: one gives you a working loop to refactor; the other gives you named interfaces, a test suite, and a recorded recovery_path out of the box.
What This Means For Experienced Engineers
Both implementations retry, classify failures, repair arguments, and emit metrics. Neo MCP did not eliminate those problems. It formalized them.
The four differences you can verify in source without argument:
- Multi-class
decide_next_action(retry / modify / switch / abort / proceed) vs binary transient/deterministic - Backoff with jitter vs plain exponential backoff
- Dedicated
_repair_argswith explicit column remapping vs implicit reasoner mutation - pytest + multi-seed harness vs a manual
run.pyharness only
Those are the rows worth leaning on in any summary. Everything else is a matter of code organization, not capability presence.
Capability Comparison
Both implementations pass the benchmark. The table below compares how recovery is structured, not whether it exists. Every cell is checkable against the repo.
| Capability | Claude Code | Claude Code + Neo MCP |
|---|---|---|
| Functional agent | Yes | Yes |
| Retry handling | Yes | Yes |
| Failure classification | Binary (transient vs deterministic) | Multi-class (decide_next_action: retry / modify / switch / abort / proceed) |
| Backoff strategy | Exponential | Exponential with jitter |
| Argument repair | Implicit (reasoner mutates args) | Dedicated _repair_args with explicit remapping |
| Planner swapping | By shared method signature | Formal PlannerInterface ABC |
| Recovery observability | Metrics dict | Metrics dict plus recorded recovery_path |
| Automated tests | None (manual harness) | pytest suite plus multi-seed harness (seed 7 codified partial) |
Run it yourself
Clone the repository and run either implementation:
# Implementation A (Claude Code only)
cd claudecode
python3 run.py
# Implementation B (Claude Code + Neo MCP)
cd neo-mcp
python3 main.py
Run the Neo MCP test suite:
cd neo-mcp
pip install -r requirements-dev.txt
python3 -m pytest tests/ -v
Try a different flakiness draw with AGENT_SEED=8 python3 run.py (seeds 8/9 can surface the give-up path). Full execution logs and per-attempt repair traces are captured in each folder's execution_log.txt / execution_log.md.
The Biggest Takeaway
The benchmark did not show that Neo MCP writes dramatically different code. Both agents recover from flaky tools and hallucinated arguments.
What Neo MCP adds are four concrete, source-verifiable edges: multi-class decide_next_action, jittered backoff, a dedicated _repair_args function, and a pytest multi-seed test suite. Those are the claims that survive technical diligence.
Beyond that, Neo MCP formalizes recovery into named interfaces and recorded recovery_path steps. Claude Code does the same work ad hoc inside a single agent loop. For teams extending the system, that formalization is the practical difference, not a missing capability on either side.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor