
RAGPrep: One-Command Document Ingestion for Local-First RAG
The Problem
Building RAG sounds easy right up until you have to ingest real documents. PDFs with multi-column layouts. DOCX files with embedded images. PPTX decks where the content is in the speaker notes. Tables that span pages. The "parse, chunk, embed, store" pipeline always breaks at step one, and when it breaks every downstream stage inherits the damage. Half a table retrieved from a vector DB is worse than no table.
NEO built RAGPrep to make this boring and reproducible: one command turns a folder of mixed-format documents into a queryable vector store, with chunking that respects document structure and an OpenAI-compatible query endpoint that runs entirely on your machine.
Parsing Through markitdown
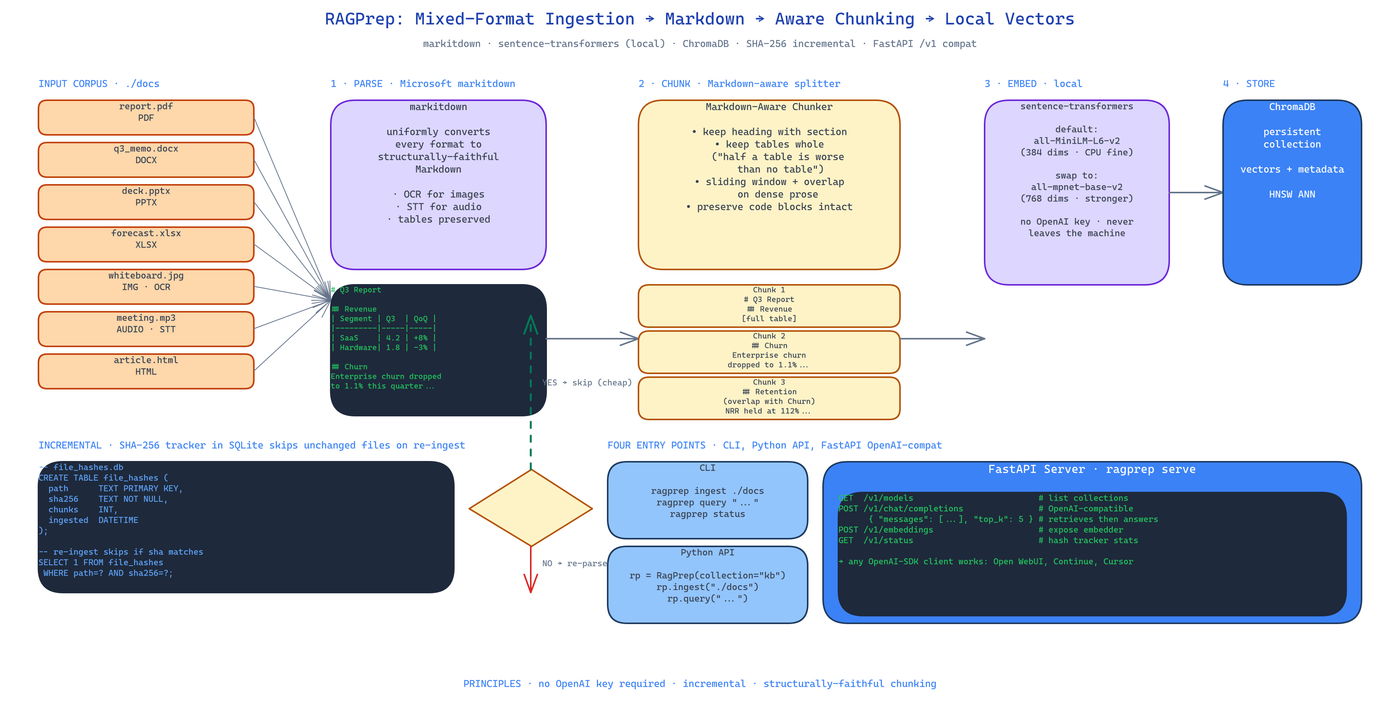
Microsoft's markitdown is the parsing layer. It converts PDF, DOCX, PPTX, XLSX, images, audio, and HTML into clean Markdown before anything else touches them. This matters because once every format is Markdown, the rest of the pipeline has one job — chunking Markdown — instead of seven jobs — chunking seven different formats badly.
Images go through OCR. Audio goes through speech-to-text. Spreadsheets are preserved as Markdown tables. The output is structurally faithful: headings stay headings, tables stay tables, lists stay lists.
Markdown-Aware Chunking
This is where most RAG pipelines go wrong. They use fixed-token or fixed-character splits that cut through sentences, split tables mid-row, and orphan headings from their content. RAGPrep chunks by Markdown structure:
- Each section keeps its heading attached. When the retriever returns chunk N, the user sees the section title, not a floating paragraph.
- Tables are kept whole. Splitting a four-row table into two two-row chunks is a bug; RAGPrep treats tables as atomic.
- Dense prose uses a sliding window with overlap to avoid semantic cliffs at chunk boundaries.
The repo's maxim: half a table is worse than no table. The chunker is built around that.
Local-First Embeddings
Embeddings are computed locally with sentence-transformers. The default model is all-MiniLM-L6-v2 — 384 dimensions, CPU-friendly, good enough for most document QA. You can swap to all-mpnet-base-v2 for higher fidelity or to a domain-specific model by changing one line of config.
No OpenAI API key. No network calls at embedding time. Your documents never leave the machine.
Incremental Hash Tracking
SHA-256 of every file is stored in SQLite at ingestion time. On the next run, files whose hashes have not changed are skipped entirely — no re-parsing, no re-embedding, no ChromaDB churn. For a document collection that grows over time this makes re-ingestion cheap: only the diff gets processed.
Four Ways to Use It
ragprep ingest ./docs # CLI ingestion
ragprep query "question" # CLI query
ragprep serve # FastAPI server with OpenAI-compatible /v1/chat/completions
ragprep status # hash tracker + collection stats
The serve subcommand is the one that unlocks downstream integration. Any tool that speaks the OpenAI chat API — Open WebUI, Continue, a custom React frontend, another LLM agent — can point at http://localhost:8000/v1 and get RAG-augmented responses without knowing RAGPrep exists.
Python API
For embedding into your own app:
from ragprep import RagPrep
rp = RagPrep(collection="knowledge")
rp.ingest("./docs")
answers = rp.query("what did the Q3 report say about churn?", top_k=5)
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a local-first RAG ingestion pipeline in Python. Use Microsoft markitdown to parse PDFs, DOCX, PPTX, XLSX, images, audio, and HTML into Markdown. Chunk with Markdown-aware rules: keep headings with sections, keep tables whole, use sliding-window overlap for dense prose. Embed locally with sentence-transformers all-MiniLM-L6-v2. Store vectors in ChromaDB. Track file SHA-256 in SQLite for incremental re-ingestion — skip unchanged files. Expose four entry points: CLI ingest/query/status, FastAPI server with OpenAI-compatible /v1/chat/completions, and a Python API. No OpenAI API key required for core operation."
NEO scaffolds the parsing, chunking, embedding, and storage layers. From there you iterate — add a re-ranker on top of ChromaDB retrieval, plug the FastAPI server into an Open WebUI frontend, or extend the chunker with a domain-specific rule for code blocks.
NEO built a one-command local-first RAG ingestion pipeline with Markdown-aware chunking, incremental hash tracking, and an OpenAI-compatible query endpoint. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor