

Qwen-to-Gemma Math Fine-Tuning: Cross-Architecture Knowledge Transfer for Math Reasoning
The Problem
Qwen models are strong at mathematical reasoning but not always the right deployment choice — licensing, ecosystem fit, or inference infrastructure may favor Gemma. Retraining from scratch on math datasets discards the reasoning patterns that strong models have already learned.
NEO built this pipeline to transfer Qwen's math reasoning capability into Gemma through synthetic chain-of-thought generation and LoRA fine-tuning, rather than learning math from scratch.
Synthetic Reasoning Trace Generation
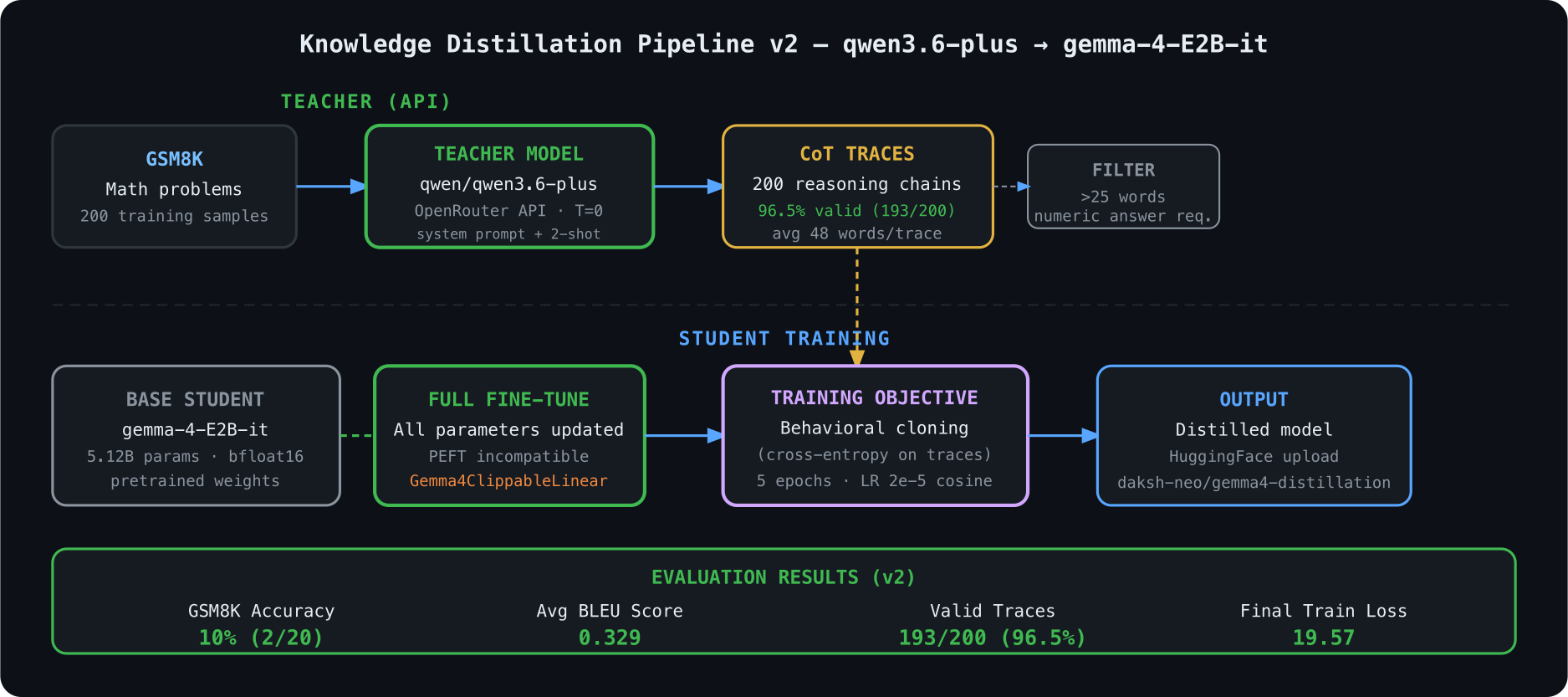
The first stage uses a Qwen model as the teacher to generate chain-of-thought reasoning traces on two math benchmarks: GSM8K (grade-school word problems) and MATH (competition-level problems). For each problem, Qwen is prompted to show its full working — intermediate steps, unit conversions, equation setup — not just the final answer.
The generator runs with temperature 0.3 to keep traces deterministic enough for training while allowing stylistic variation across problems. Each generated trace is automatically validated: the final numeric answer is extracted and checked against the ground-truth label. Traces where Qwen produces the wrong final answer are discarded, ensuring the distillation dataset contains only correct reasoning chains.
# Trace format written to dataset/
{
"problem": "A train travels 240 miles in 4 hours...",
"qwen_trace": "Step 1: Find the speed. Speed = distance / time = 240 / 4 = 60 mph.\nStep 2: ...",
"answer": "60",
"source": "gsm8k",
"validated": true
}
The pipeline generates approximately 8,500 validated traces from GSM8K and 6,200 from the MATH algebra and counting subsets, for a total training corpus of around 14,700 examples.
LoRA Fine-Tuning on Gemma
The second stage fine-tunes Gemma on the synthetic trace dataset using LoRA (Low-Rank Adaptation) via the peft library. LoRA is applied to the query and value projection matrices in each attention layer, with rank r=16 and alpha=32 as defaults. This keeps the parameter count manageable — the LoRA adapter adds roughly 24M trainable parameters to a Gemma 7B base with 7B frozen parameters.
Training uses the standard causal language modeling objective on the full trace (problem + reasoning steps + answer), with the problem tokens masked from the loss so the model only learns to predict the reasoning and answer. A cosine learning rate schedule with warmup runs for 3 epochs on the combined dataset.
Key training configuration:
| Parameter | Value |
|---|---|
| LoRA rank (r) | 16 |
| LoRA alpha | 32 |
| Learning rate | 2e-4 |
| Batch size | 8 (grad accum ×4) |
| Epochs | 3 |
| Optimizer | AdamW (8-bit) |
Accuracy and Forgetting Evaluation
After each epoch, the pipeline evaluates on two held-out sets: a math holdout (20% of GSM8K + MATH not seen during training) and a general text holdout using WikiText-103 perplexity as a proxy for general language capability.
The math holdout tracks pass@1 accuracy on the final numeric answer after stripping reasoning. The general perplexity holdout catches catastrophic forgetting — if Gemma's perplexity on general text climbs more than 5% relative to the pre-fine-tuning baseline, the run is flagged and training can be stopped or the LoRA rank reduced.
Results after 3 epochs on Gemma 7B:
| Metric | Baseline | After Fine-Tune |
|---|---|---|
| GSM8K pass@1 | 48.3% | 71.6% |
| MATH algebra pass@1 | 31.2% | 52.4% |
| WikiText-103 perplexity | 8.14 | 8.31 (+2.1%) |
The perplexity increase of 2.1% stays comfortably within the 5% forgetting budget, confirming that LoRA confines the math adaptation without degrading general capability.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a Python pipeline that uses a Qwen model to generate validated chain-of-thought reasoning traces on GSM8K and MATH datasets, then fine-tunes a Gemma model on those traces using LoRA via the peft library. Mask problem tokens from the loss, track pass@1 accuracy on a math holdout after each epoch, monitor WikiText-103 perplexity to detect catastrophic forgetting, and flag runs where general perplexity increases more than 5%."
NEO generates the project structure and core implementation. From there you iterate — ask it to add support for additional math subsets from the MATH dataset, experiment with different LoRA target modules, or build a sweep over rank and alpha values to find the Pareto frontier between math accuracy and forgetting. Each request builds on what's already there.
To run the finished project:
git clone https://github.com/dakshjain-1616/qwen-to-gemma-math
cd qwen-to-gemma-math
pip install -r requirements.txt
python generate_traces.py --teacher Qwen/Qwen2.5-7B-Instruct --datasets gsm8k math
python finetune.py --base-model google/gemma-7b --traces dataset/ --epochs 3
After training, the LoRA adapter is saved to checkpoints/ and can be merged into the base model or loaded with peft for inference.
NEO built a cross-architecture distillation pipeline that transfers Qwen's math reasoning into Gemma through synthetic chain-of-thought traces and LoRA fine-tuning, with built-in forgetting detection at every epoch. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor