

Is Open Deep Research Production-Ready? A Repo-Grounded Audit, and the Lessons for Anyone Building Agent Systems
We ran a citation-by-citation production-readiness audit of a popular open-source "deep research" agent framework. The verdict (excellent prototype, not production-ready) is less interesting than why, and what every team building agent systems should take from it.
⏱ 10-min read · For: engineering leaders, AI platform teams, anyone about to build on (or borrow patterns from) an open-source agent framework
TL;DR
- The subject:
langchain-ai/open_deep_research, a supervisor that spins up parallel researcher sub-agents to do automated deep research. We audited it at commit68fb7ab, with every finding tied to a verifiedfile:line. - The verdict: a genuinely clean architecture (three-level nested
StateGraph, structured outputs with retry, real multi-tenant auth), but not production-ready: no unit tests, no CI gate, near-zero observability, no cost controls, no timeouts, and a one-line bug that silently ends research on any error. - The point: none of these gaps are unique to this repo. They are the default failure profile of agent frameworks optimized for experimentation, and that's what makes them worth studying.
- The method: repository-grounded, evidence-driven analysis, read the source, cite the line, then verify the citation against the code. (Tooling: Claude Code + NEO MCP. More on that at the end; it's the camera, not the subject.)
Why audit a framework you didn't write?
Open Deep Research is a popular reference implementation for agentic "deep research", a supervisor that delegates to parallel researcher sub-agents, each running search tools, compressing findings, and feeding a final report. If you're about to build a product on top of it (or lift its patterns), you want to know two things: how is it actually built, and what breaks when you put it under load?
That's a due-diligence question, and the honest version is tedious: read the whole codebase, trace the graph, find the error handling, check the CI, map the dependencies, then translate all of it into risk. The interesting part isn't that we automated the reading. It's what the reading revealed about a pattern that repeats across nearly every agent framework in the wild.
How we investigated
The method matters more than the tool, so here's the method:
- Repository-first, not docs-first. Clone the actual code; ignore the marketing. Read
deep_researcher.py,configuration.py,state.py,prompts.py,utils.py, the auth middleware, the legacy implementations, the tests,pyproject.toml,langgraph.json, and the CI workflows, end to end. - Trace the real execution path. Map the graph as it's compiled, not as it's described: a main graph (clarify → research brief → supervisor → final report) wrapping a supervisor subgraph that delegates to parallel researcher subgraphs.
- Cite everything to a
file:line. An observation without a location is an opinion. - Verify every citation against the source. This is the step most "AI-assisted" analysis skips, and the one that separates a credible audit from a plausible one. (We caught real citation errors doing this; see the end.)
The output was a 15-section report. What follows is the part that generalizes.
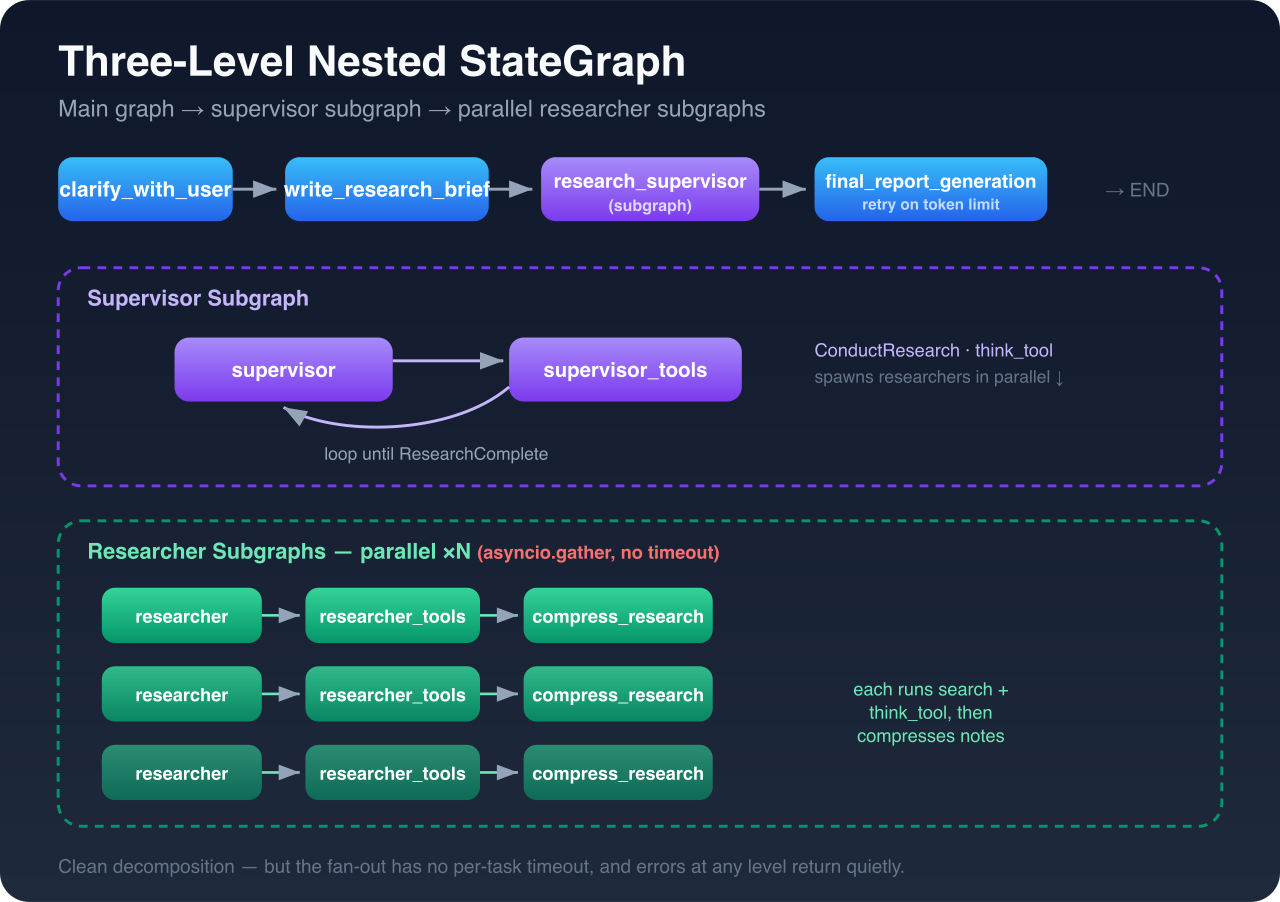
What it found, and why it matters
Each finding below is a real artifact in the code. The reason to care is the principle underneath it, which holds for almost any agent system.
🔴 A one-line bug that silently ends research
In supervisor_tools, the error handler reads:
if is_token_limit_exceeded(e, configurable.research_model) or True:
# ... end the research phase, return partial results
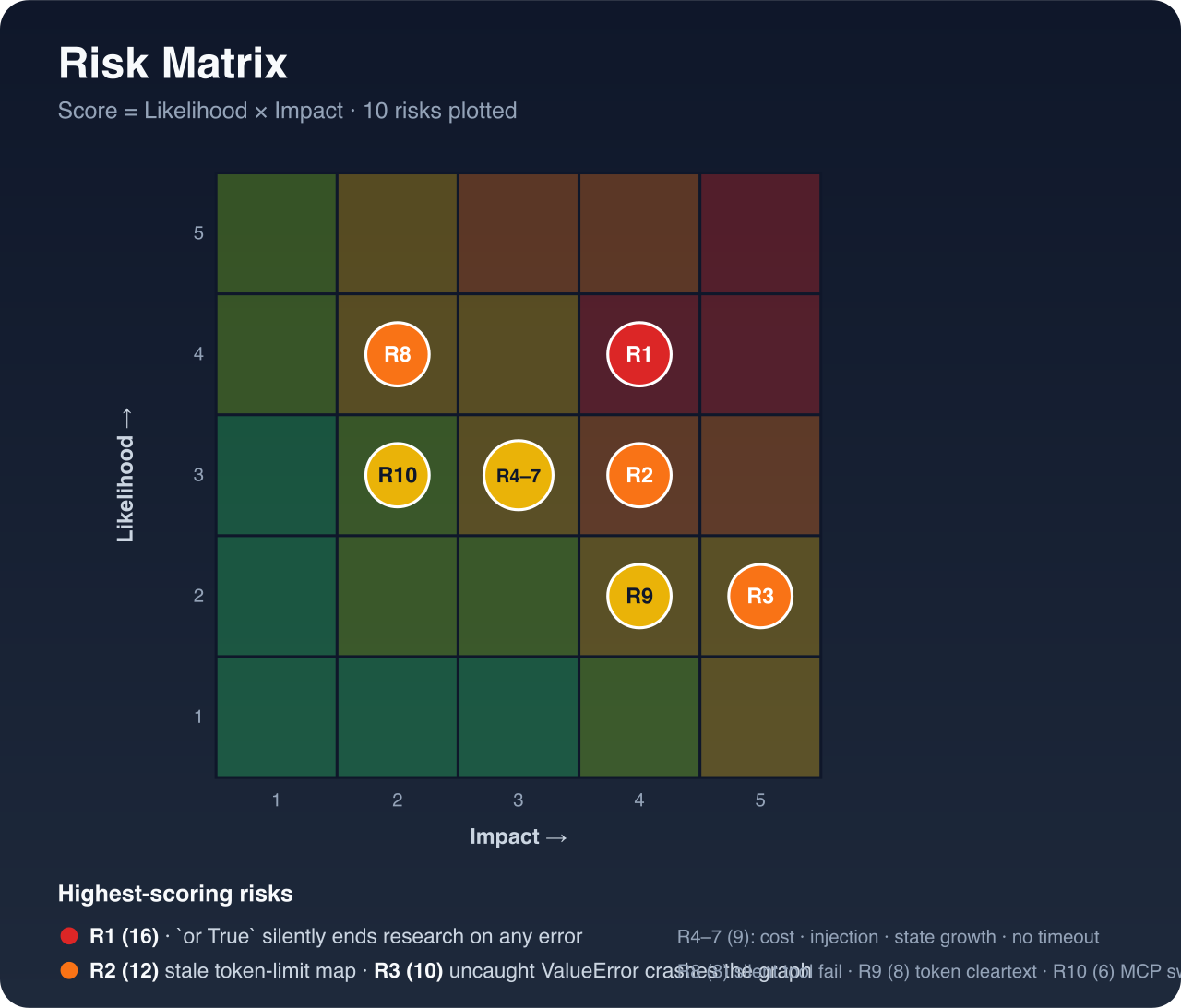
The or True makes the branch unconditional. Any exception (a transient network blip, a tool error, anything) ends the research phase and returns whatever was collected so far, with no retry and nothing surfaced. One line (deep_researcher.py:334); the highest-scoring risk in the report (16/25).
The principle: Agents fail silently by default. A traditional service that swallows an exception returns a 500 someone notices. An agent that swallows one returns a confident, shorter answer, and degraded output is indistinguishable from correct output unless you design for it. The most dangerous agent failures aren't crashes; they're plausible partial results. Generalizes? Universally. Any agent that catches-and-continues needs to treat "I gave up early" as a first-class, observable outcome, not a quiet
return.
🔴 A tests/ directory with zero unit tests
It looks reassuring until you open it: it's entirely LangSmith evaluation harnesses and benchmarks. There is no unit test for any function, state reducer, graph node, or tool.
The principle: Evals are not tests. Agent teams often build sophisticated eval suites (great for measuring quality) while having nothing that pins deterministic behavior, does the reducer merge correctly, does the router branch correctly, does config parse. Evals tell you the model got better or worse; tests tell you you didn't break something. You need both, and the presence of one is routinely mistaken for the other. Generalizes? Strongly. "We have evals" is the most common false-confidence signal in agent codebases.
🟠 Almost no observability
The main graph has zero logging calls and no trace context across its three levels. Debugging a production failure means editing source and redeploying.
The principle: You cannot operate what you cannot see. Agent control flow is non-deterministic and multi-step; without per-node structured logs and trace propagation, a failure in a sub-agent three levels down is effectively undebuggable in production. Observability is not a phase-two nicety for agents, it's the only way to run them at all. Generalizes? Universally, and it gets worse as the graph deepens.
🟠 Parallel work with no timeout
The supervisor fans researchers out with asyncio.gather(...) and no timeout (deep_researcher.py:300-305). One researcher hitting a hanging API blocks the whole supervisor indefinitely.
The principle: Fan-out without a deadline is a liveness bug. The moment you parallelize sub-agents, the slowest (or stuck) one becomes your latency floor, and with no timeout, your availability floor. Every concurrent dispatch needs a per-task deadline and a partial-results strategy. Generalizes? Any system using
gather/Promise.allover external calls.
🟠 No cost controls
max_concurrent_research_units defaults to 5 and max_react_tool_calls to 10, so a single run can fan out to 50+ LLM calls and 50+ search calls, with no budget enforcement anywhere.
The principle: In agent systems, cost is a runtime variable, not a line item. A recursive/fan-out agent's spend is a function of inputs you don't control at deploy time. Without a per-run budget ceiling, one pathological query can cost 100× a normal one. Treat tokens like you'd treat unbounded recursion. Generalizes? Any agent with loops or fan-out, i.e., all of them.
🟡 The quieter ones
A stale hardcoded MODEL_TOKEN_LIMITS map (utils.py:788-829) that returns None for unknown models, so truncation fails on the first retry instead of degrading; four broad except Exception blocks that can't tell transient from permanent errors; unbounded note accumulation in state; CI that runs only AI review bots; and legacy code bundled into the production package. Each is a small thing; together they're the texture of "prototype."
These rolled up into a production-readiness scorecard, clean architecture and strong docs, undermined by testing, observability, and CI sitting at the floor:
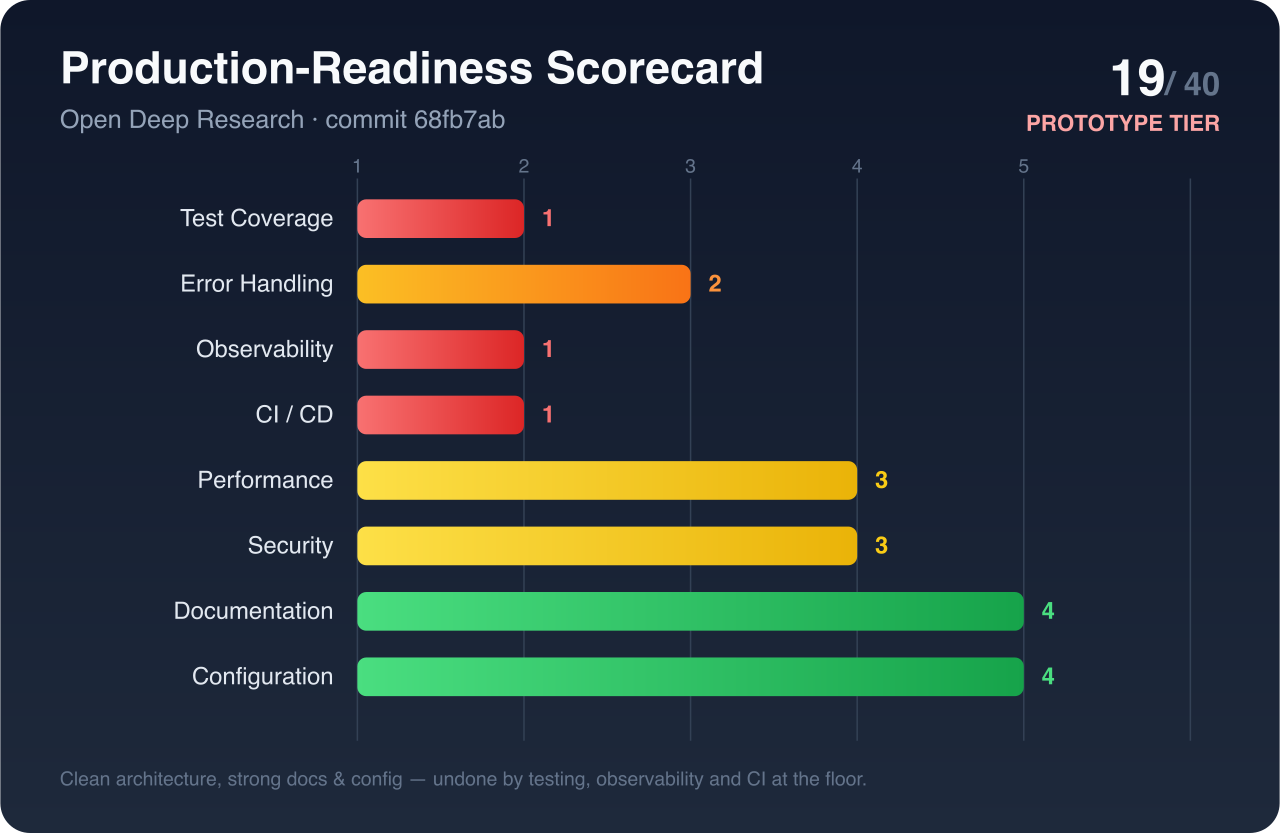
| Dimension | Score (1–5) | Dimension | Score (1–5) |
|---|---|---|---|
| Test Coverage | 1 | Performance | 3 |
| Error Handling | 2 | Security | 3 |
| Observability | 1 | Documentation | 4 |
| CI/CD | 1 | Configuration | 4 |
The verdict: an excellent research prototype and reference architecture, not a production system. The gaps are precisely the distance between "reference implementation" and "something you'd run unattended for paying users."
Plotted by likelihood and impact, the risks cluster exactly where you'd fear in an under-instrumented agent, reliability and cost, with one critical outlier:
What surprised us
The defects were predictable. The discoveries were not.
- The architecture is genuinely good. A three-level nested
StateGraphwith cleanly separated supervisor and researcher subgraphs is better structured than a lot of code that's already in production. Decomposition was not the weak point, operability was. Lesson: clean architecture and production-readiness are independent axes. You can have one without the other, and this repo has exactly the surprising half. - They solved the agent failure mode everyone forgets, and missed the ones everyone assumes are handled. Structured outputs are wrapped in
.with_retry()throughout, meaning the team clearly thought hard about parsing failures (a top-three agent footgun). Yet error handling around tool execution is where it falls down. Sophistication in one failure domain told us nothing about the others. - There's real multi-tenant auth in a "reference" project. Supabase-JWT middleware with per-resource handlers is more than most demos ship. It signals the project has production aspirations, which makes the missing test/observability layers more of a gap than an excuse.
- Excellent docs, near-zero observability. Documentation scored 4/5; observability scored 1/5. Good docstrings are not operability. A well-documented system you can't see into at runtime is still a black box when it breaks.
- The scariest bug looked intentional.
or Truereads like a debugging override someone left in,# token limit OR (for now) anything → bail. The most dangerous bugs aren't exotic; they're plausible one-liners that pass code review because they look deliberate.
Lessons for anyone building agent systems
Pulled out so you can apply them without ever touching this repo:
- **Testing , ** Build deterministic unit tests for the plumbing (reducers, routers, config parsing, tool wrappers) and keep them separate from evals. Evals measure model quality; tests protect you during refactors. Shipping only evals is shipping no tests.
- **Reliability , ** Every fan-out gets a per-task timeout and a defined partial-results path. Distinguish transient (retryable) from permanent (fail-fast) errors explicitly, a bare
except Exceptionerases the difference you most need. - **Observability , ** Instrument before you scale, not after the first incident. Per-node structured logs + trace context that propagates through the whole graph. If a sub-agent three levels down can fail without leaving a trace, you don't have a production system.
- **Cost control , ** Put a hard per-run budget ceiling on any agent with loops or fan-out. Track spend as state and interrupt when exceeded. Assume an adversarial or pathological input will try to maximize your bill.
- **Failure handling , ** Make "the agent gave up / returned partial results" a loud, first-class, observable event. Silent degradation is the defining risk of agent systems because bad output and good output look the same.
- **Productionization , ** Treat clean architecture as table stakes, not the finish line. The work between "it runs in a demo" and "it runs unattended for customers" is almost entirely non-functional: tests, observability, error taxonomy, budgets, timeouts, CI gates.
What would be required for production
A concrete roadmap, in priority order:
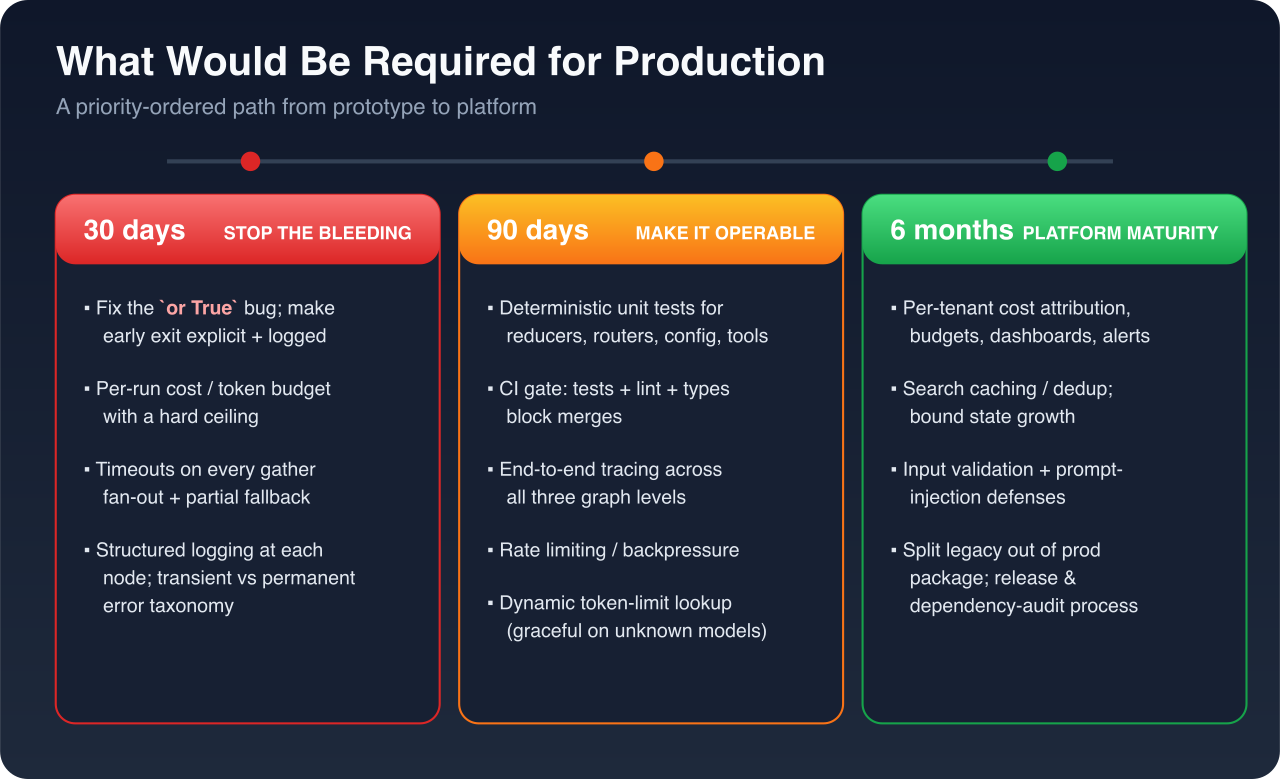
First 30 days: stop the bleeding
- Fix the
or Truebug; make early termination an explicit, logged decision. - Add a per-run cost/token budget with a hard ceiling and interrupt.
- Add timeouts to every
gatherfan-out, with a partial-results fallback. - Add structured logging at each node and a real error taxonomy (transient vs permanent).
First 90 days: make it operable
- Build a deterministic unit-test suite for reducers, routers, config, and tool wrappers; wire a CI gate (tests + lint + type-check) that blocks merges.
- Add end-to-end trace propagation (e.g. OpenTelemetry) across all three graph levels.
- Add rate limiting / backpressure and a health/readiness endpoint.
- Replace the hardcoded token-limit map with a dynamic lookup that degrades gracefully on unknown models.
First 6 months: platform maturity
- Cost attribution and budgets per tenant/run; spend dashboards and alerts.
- Caching/deduplication for repeated searches; bound state growth.
- Input validation and prompt-injection defenses on user-supplied topics.
- Split legacy/experimental code out of the production package; formal release and dependency-audit process.
How we kept it honest
The credibility of an audit lives or dies on its evidence, so the last step was verification: re-check every file:line against the source at commit 68fb7ab.
It mattered. On the first pass, several citations were wrong, the or True bug was a couple of lines off, a few utils.py functions were attributed to the wrong ranges entirely, and one pointed at a docstring instead of the error handler it described. The findings were real; the coordinates weren't, and an evidence index with wrong coordinates is worthless. Each was corrected against the clone before publishing.
The transferable habit: repo-grounded claims are cheap to verify and expensive to fake, so verify them. Whether the first draft comes from a junior engineer, a consultant, or an AI agent, "trust, then check the line numbers" is what turns a fast analysis into a defensible one.
This is an independent technical review of public, open-source code, offered constructively. Open Deep Research is a strong prototype; the gaps noted here are the expected work of productionizing any reference implementation. Full report with all 15 sections and the verified evidence index: OPEN_DEEP_RESEARCH_DUE_DILIGENCE.md.
Tooling note: the investigation was run from inside Claude Code, which dispatched the repository reading and report drafting to NEO MCP (a local agent execution layer) and then verified the output. The method (repository-grounded, evidence-verified analysis) is the point; the tools are interchangeable.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor