

NeuralUCB Router: Bandit-Based LLM Routing for Cost-Quality Optimization
The Problem
Routing every query to GPT-4 is expensive. Routing everything to a cheaper model costs quality. Static rule-based routers require manual tuning that goes stale as query distributions shift.
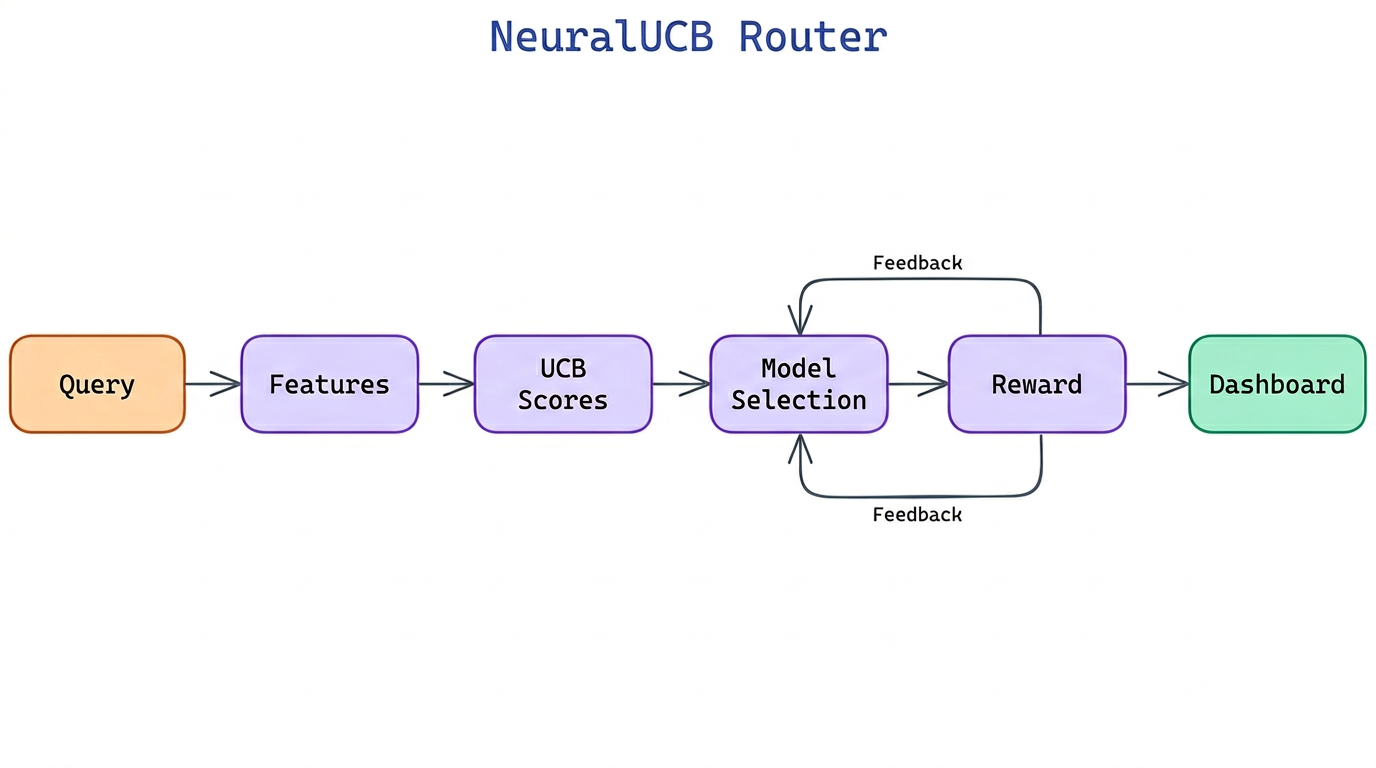
NEO built NeuralUCB Router to learn the routing policy from live traffic: it uses Neural Upper Confidence Bound to maintain per-model reward estimates with exploration bonuses, automatically discovering which query types a cheaper model handles well and routing accordingly — without manual rules or labeled training data.
NeuralUCB: Reward Estimation with Exploration
NeuralUCB Router models routing as a contextual bandit problem. Each incoming query is the context, each available model is an arm, and the reward is a combination of response quality and cost. The router maintains a small neural network per model that maps query features to a predicted reward. At decision time it selects the model with the highest Upper Confidence Bound score:
UCB(model_i) = predicted_reward(model_i, query) + alpha * uncertainty(model_i, query)
The alpha parameter controls the exploration-exploitation trade-off. Early in deployment, high uncertainty drives exploration across all models. As the reward network accumulates data, uncertainty narrows and the router converges on cost-optimal routing for well-understood query types while preserving exploration for novel patterns.
Query features are extracted using a lightweight sentence embedding (MiniLM-L6-v2 by default) plus a set of structural features: query length, presence of code blocks, number of entities, question type classification (factual, reasoning, creative), and domain signal from keyword matching. These 128-dimensional feature vectors are the input to each model's reward network.
Reward Signals and Quality Scoring
NeuralUCB Router supports three reward signal sources that can be combined with configurable weights:
Automatic scoring evaluates responses without human input. For factual queries, it checks answer consistency across two sampled responses from the selected model. For coding queries, it runs syntax validation and, if a test suite is provided, executes the tests. Semantic coherence is measured using cosine similarity between the query embedding and response embedding.
Human feedback is collected through an optional lightweight feedback endpoint (POST /feedback) that accepts thumbs up/down signals and optional rubric scores. These are stored and used as high-weight training examples for the reward networks.
Cost-adjusted reward applies a cost penalty based on the model's per-token price and the actual token count of the response. The net reward formula is:
reward = quality_score - cost_weight * (input_tokens * price_in + output_tokens * price_out)
cost_weight is tunable: set it to 0 for pure quality optimization, or increase it to push the router toward cheaper models when quality differences are small.
Supported Models and Deployment
The router supports any OpenAI-compatible API endpoint, covering GPT-4o, GPT-4o-mini, Claude 3.5 Sonnet, Claude 3 Haiku, Gemini 1.5 Pro and Flash, and locally-served models via Ollama or vLLM. Model configurations are defined in a YAML file with API keys, base URLs, per-token pricing, and maximum context length.
models:
- id: gpt-4o
api_base: https://api.openai.com/v1
price_in: 0.0000025
price_out: 0.00001
max_context: 128000
- id: phi-3-mini-local
api_base: http://localhost:11434/v1
price_in: 0.0
price_out: 0.0
max_context: 4096
The router exposes an OpenAI-compatible /v1/chat/completions endpoint, making it a drop-in replacement for direct model API calls. Routing decisions and reward signals are logged to a local SQLite database and viewable through a built-in stats dashboard at /dashboard.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build an LLM router in Python that uses Neural Upper Confidence Bound (NeuralUCB) to learn which model to route each query to. Extract query features using sentence embeddings plus structural features like query length, code presence, and question type. Maintain a per-model neural reward network that predicts quality minus cost, with an exploration bonus based on prediction uncertainty. Support automatic quality scoring, optional human feedback, and any OpenAI-compatible model endpoint. Expose an OpenAI-compatible /v1/chat/completions endpoint and a dashboard showing routing decisions and reward trends."
NEO generates the project structure and core implementation. From there you iterate — ask it to add A/B testing mode that holds out a fraction of traffic to test new models, build per-user routing profiles that adapt to individual quality preferences, or export routing policy snapshots for reproducible deployments. Each request builds on what's already there.
To run the finished project:
git clone https://github.com/dakshjain-1616/neuralucb-router
cd neuralucb-router
pip install -r requirements.txt
cp models.yaml.example models.yaml # add your API keys
python -m neuralucb_router --port 8000
Point your application at http://localhost:8000/v1 instead of a model API directly, and the router begins learning the optimal routing policy from your live traffic.
NEO built a NeuralUCB-based LLM router that learns cost-quality routing policies from live query traffic without manual rules, supporting any OpenAI-compatible model including local deployments. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor