

Building a Multi-Model Invoice OCR Pipeline with Vision Transformers and BERT
The Problem
Invoice processing sounds simple until you're staring at 50 different invoice formats from 50 different vendors, each with its own layout quirks. Template-based systems break almost immediately. Rule-based parsers require constant maintenance. Standard OCR tools read text fine — but "April 15, 2024" could be an invoice date, a due date, or a service period, and "$4,200.00" could be a subtotal, a line item, or a total. Without structure-aware extraction, you're left doing post-processing guesswork on financial data where errors have real consequences.
NEO built a two-stage pipeline that fuses vision-based OCR with specialized entity extraction, and the results are strong enough for production.
Two-Stage Architecture
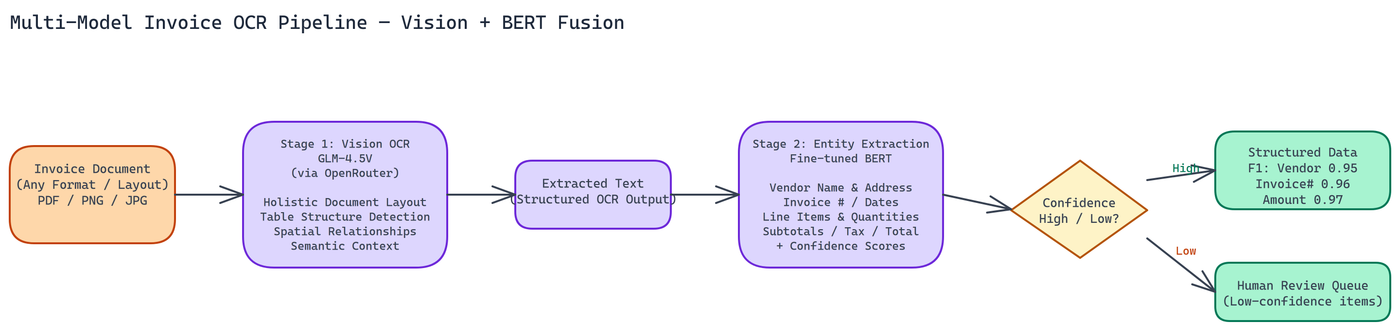
The pipeline operates in two sequential stages, each specialized for a different kind of understanding.
Stage 1: Vision-Based Text Extraction with GLM-4.5V
The pipeline uses GLM-4.5V via OpenRouter for the initial OCR pass. Unlike traditional OCR engines, vision transformers process the entire document layout holistically. They capture spatial relationships between elements, understand table structures, and maintain document semantics during extraction.
This matters because an invoice isn't just a list of text tokens. The proximity of a number to a label, the visual hierarchy of sections, the grouping of line items in a table: all of these carry meaning. GLM-4.5V handles this naturally.
OpenRouter's pricing model keeps costs reasonable for high-volume processing, which is important when you're running this against thousands of invoices per month.
Stage 2: Entity Classification with Fine-Tuned BERT
Raw extracted text still needs to be mapped to structured fields. NEO fine-tuned a BERT model specifically for invoice entity recognition, training it to classify and extract:
- Vendor name and address
- Invoice number and date
- Due date and payment terms
- Line item descriptions, quantities, and unit prices
- Subtotals, taxes, and total amounts
Beyond classification, the model outputs a confidence score for each identified field. This is critical for production systems. You want to know when the model is uncertain so you can route those documents to a human reviewer rather than silently producing bad data.
Performance on Real Invoice Data
NEO benchmarked the pipeline across a diverse set of invoice samples covering different industries, layouts, and document quality levels. The results:
- Vendor identification: 0.95 F1-score
- Invoice number extraction: 0.96 F1-score
- Amount extraction: 0.97 F1-score
The amount extraction score is particularly meaningful because financial accuracy is non-negotiable. Getting a total amount wrong cascades into accounting errors.
Why Multi-Model Fusion Works Here
Single-model approaches force a trade-off: great OCR with mediocre entity understanding, or a large multimodal model that handles everything but costs more to run and is harder to fine-tune.
The two-stage design lets each model do what it does best. GLM-4.5V handles the visual complexity of document understanding. The fine-tuned BERT handles domain-specific semantic classification. You can also swap out either component independently if a better model emerges for one of the stages.
Practical Deployment
The pipeline ships with a single entry point: run_project.py. It handles dependency verification, downloads the required model weights, processes sample invoices, and writes structured results. Setup takes about ten minutes and works out of the box.
Requirements are minimal: Python 3.10+, an OpenRouter API key (available free at openrouter.ai), and the BERT model weights. The API key is the only ongoing cost, and it's priced per token rather than per document.
Use Cases Beyond Invoice Processing
The same architecture works for any structured document extraction task: purchase orders, receipts, contracts, shipping manifests. If the document type has consistent field semantics even when layouts vary, this two-stage approach handles it well.
NEO has also applied variations of this pipeline to expense report processing, customs documentation, and vendor statement reconciliation.
What's Next
The natural extension is a feedback loop where corrected extractions from human reviewers feed back into the fine-tuning dataset. Over time, the BERT model improves on the specific document types your organization processes most often.
NEO is also experimenting with streaming outputs so that partial results are available before the full pipeline completes, useful for interactive applications where users want to see extraction in progress.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a two-stage invoice OCR pipeline in Python. Stage 1 uses GLM-4.5V via OpenRouter to perform vision-based text extraction that understands document layout and table structure holistically. Stage 2 uses a fine-tuned BERT model for entity classification and extraction, identifying vendor name and address, invoice number and date, due date and payment terms, line item descriptions and quantities and unit prices, and subtotals, taxes, and totals. Each extracted field should include a confidence score, and fields below a confidence threshold should be flagged for human review rather than passed downstream silently. Provide a single-file entry point that handles dependency verification, downloads BERT weights on first run, processes invoices from a samples/ directory, and writes structured JSON results to results/."
NEO generates the project structure and core implementation. From there you iterate: ask it to implement the GLM-4.5V prompt that extracts layout-aware text with spatial relationship preservation, fine-tune the BERT model on invoice entity labels with the full field taxonomy, or add the confidence threshold routing that flags uncertain extractions for human review. Each follow-up builds on what's already there.
To run the finished project:
git clone https://github.com/dakshjain-1616/Multi-Model-Invoice-OCR-Pipeline
cd Multi-Model-Invoice-OCR-Pipeline
pip install -r requirements.txt
echo "OPENROUTER_API_KEY=sk-or-..." > .env
python run_project.py
The script downloads BERT weights on first run (allow 10 minutes), then processes the sample invoices in samples/ and writes per-field confidence scores to results/. Try the pipeline on an invoice with an unusual layout to see how the two-stage fusion handles formats that would break template-based systems.
NEO built a multi-model invoice OCR pipeline where GLM-4.5V vision understanding and fine-tuned BERT entity extraction combine to achieve 95%+ accuracy across any invoice format, with confidence scores that flag uncertain extractions rather than passing bad data downstream. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor