

Automated LLM Evaluation: How NEO Built a Tool to Find the Best Model for Any Task
The Problem
Choosing the right LLM for a production task is harder than it looks. Leaderboard rankings tell you how models perform on academic benchmarks — they tell you very little about how a model will perform on your specific task, with your input distribution, evaluated against criteria that matter to your use case. The standard workaround is manual testing: pick a few models, write some test prompts, read the outputs, form an opinion. This doesn't scale, and it's too subjective to repeat reliably.
NEO built a tool that answers the actual question: given a task description, which model performs best on that task?
The Problem with Manual Evaluation
Manual evaluation is slow, subjective, and expensive to repeat when your task requirements change or new models are released.
You also end up with selection bias. Humans evaluate LLM outputs inconsistently, especially across multiple dimensions simultaneously. You might notice factual errors but miss subtle hallucinations. You might prefer a confident-sounding response over an accurate but hedged one.
A systematic, automated evaluation process produces better results and can be re-run cheaply.
How the Evaluator Works
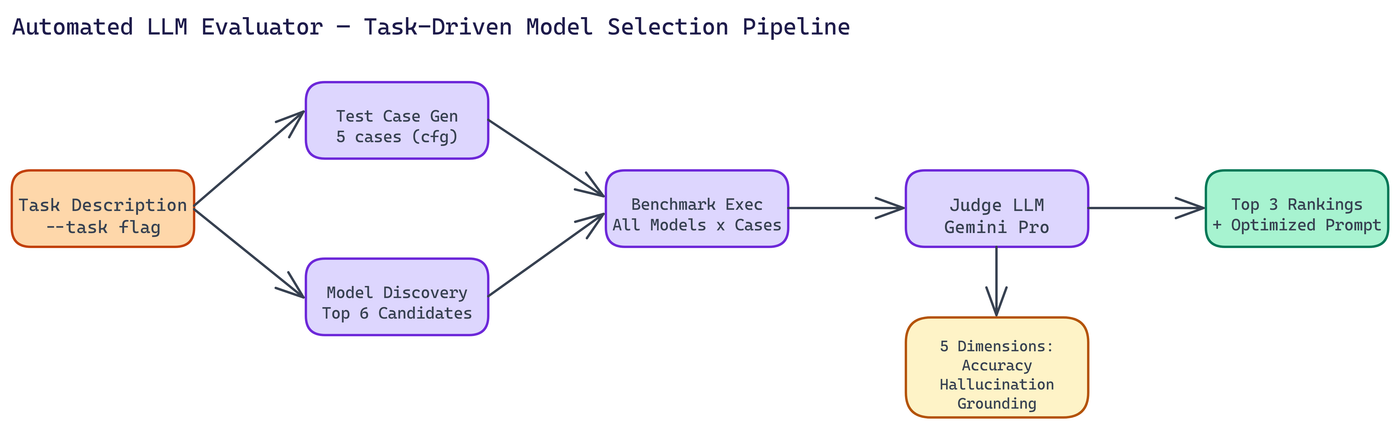
The pipeline has five steps that run automatically from a single task description.
Test case generation. The tool generates tailored test cases for your task. Not generic questions, but inputs designed to probe the specific capabilities and failure modes relevant to what you're building. By default it generates five test cases, configurable via CLI flag.
Model discovery. The tool identifies top candidate models to benchmark. Up to six candidates by default. These aren't randomly selected. The discovery step considers which models are likely to perform well given the task characteristics.
Benchmark execution. Every candidate model runs every test case. Responses are collected and stored.
Judge LLM evaluation. A Judge LLM, using Gemini Pro, evaluates each response across five dimensions: accuracy, hallucination detection, grounding, tool-calling ability, and response clarity. Each dimension is scored independently, so you can inspect the breakdown rather than just a single overall score.
Ranking and prompt optimization. The top three models are ranked by performance. The tool also produces an optimized system prompt tailored to your use case and the winning model's characteristics.
Why a Judge LLM?
Human evaluation is inconsistent. Rule-based evaluation is too rigid for open-ended text. A well-prompted Judge LLM hits a useful middle ground: consistent, multi-dimensional, and flexible enough to evaluate responses that don't have a single right answer.
The key design choice is using a separate, capable model as the judge rather than having each model evaluate itself or its competitors. Self-evaluation produces obvious biases. Cross-model evaluation is cleaner.
Separating judge and candidate also means you can upgrade the judge independently as better models become available, without changing the rest of the pipeline.
Evaluation Dimensions
The five scoring dimensions capture different aspects of response quality:
Accuracy measures whether the response is factually correct relative to ground truth or verifiable facts.
Hallucination detection looks at whether the model invents plausible-sounding but false information. This dimension is often the most important for production applications.
Grounding assesses whether claims are supported by the provided context or evidence rather than stated without backing.
Tool-calling ability matters for agentic applications where the model needs to decide when and how to use tools.
Response clarity evaluates whether the answer is well-organized and easy to understand, independent of its accuracy.
Getting a separate score for each dimension lets you make task-specific tradeoffs. For a fact-checking application, accuracy and hallucination scores matter most. For a customer-facing assistant, clarity might rank higher.
Running the Tool
Setup is quick. Clone the repository, create a virtual environment, install from requirements.txt, and set your OpenRouter API key in a .env file. Then run:
python main.py --task "your task description here"
The tool handles everything from there. You get a ranked list of the top three models, per-dimension performance metrics, and an optimized system prompt ready to use.
Optional flags let you adjust the number of test cases (--test-cases), the maximum number of candidates (--max-candidates), and the output directory (--output-dir).
Real Applications
Model selection for new projects. Before committing to a model for a production system, run the evaluator on your actual task. A few minutes of compute time will save hours of debugging later.
Regression testing after model updates. When a model provider releases a new version, re-run the evaluation to check whether performance changed on your task before updating.
Cost-performance analysis. The ranking combines with pricing information to help you decide whether a cheaper model is close enough in performance to justify the cost savings.
Prompt engineering. The optimized system prompt output is a starting point for prompt engineering, grounded in observed model behavior rather than intuition.
Evaluation is Infrastructure
Good model evaluation is infrastructure, not a one-time activity. The teams that build reliable AI systems treat evaluation as a continuous process. They run it before deploying, after updating, and when their task requirements change.
The goal of this tool is to make continuous evaluation cheap and systematic enough that teams actually do it.
Build Reliable AI Systems
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a Python CLI tool that takes a task description and automatically evaluates LLM candidates for it. The pipeline should: generate tailored test cases for the task, discover up to six candidate models via OpenRouter, run each candidate on every test case, then use Gemini Pro as a judge to score each response across five dimensions (accuracy, hallucination, grounding, tool-calling ability, and response clarity). Output a ranked top-three list with per-dimension breakdowns and an optimized system prompt for the winning model."
NEO generates the project structure and core implementation. From there you iterate: ask it to add the test case generation logic with task-specific probe design, implement the five-dimension Gemini Pro judge prompt with independent per-criterion scoring, or build the system prompt optimizer that uses observed model behavior as its input. Each follow-up builds on what's already there.
To run the finished project:
git clone https://github.com/gauravvij/llm-evaluator
cd llm-evaluator
pip install -r requirements.txt
Set credentials in a .env file, then run:
python main.py --task "Summarize legal contracts and extract key obligations, dates, and party names as structured JSON"
Try running the same task with --max-candidates 3 for a faster result, or with --test-cases 10 for a more thorough evaluation when you need higher confidence before committing to a model for production.
NEO built an automated LLM evaluator where a Judge LLM scores candidates across five dimensions - accuracy, hallucination, grounding, tool-calling, and clarity - and outputs a ranked shortlist with an optimized system prompt. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor