

Llama 3.2 3B Reasoning SFT: On-Device Chain-of-Thought via LoRA Distillation
The Problem
Edge devices like phones and Raspberry Pi cannot run cloud LLMs due to latency or privacy constraints. Existing 3B models produce single-shot answers without structured reasoning, making outputs hard to audit or verify.
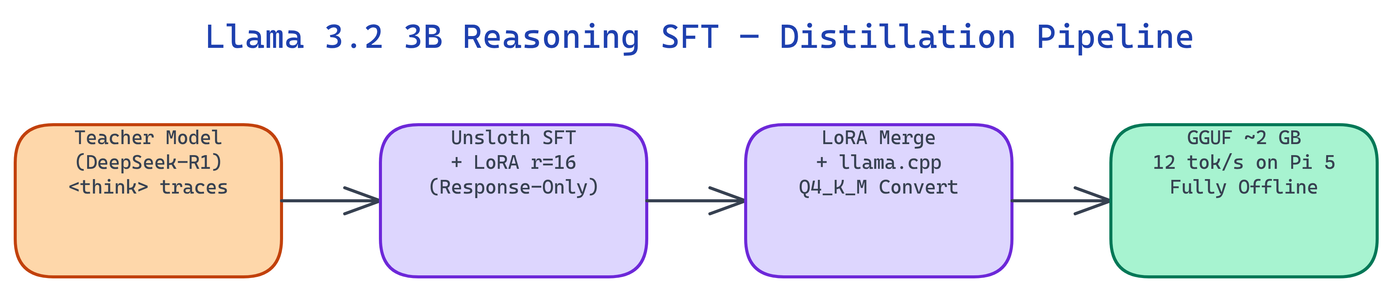
NEO built this pipeline to add <think> reasoning traces to Llama 3.2 3B via knowledge distillation, then export the result as a 2 GB GGUF that runs locally on any device with 4 GB RAM.
The Distillation Pipeline
Response-Only Training is the central technique. The model trains only on the assistant's response tokens. User prompt tokens are masked with labels = -100, so no gradient flows through them.
The label mask looks like this:
<|start_header_id|>user<|end_header_id|> → labels = -100
What is 17 × 24? → labels = -100
<|eot_id|> → labels = -100
<|start_header_id|>assistant<|end_header_id|> → labels = -100
<think> → labels = token_id ✅
17 × 24 = 17×20 + 17×4 = 340 + 68 → labels = token_id ✅
</think> → labels = token_id ✅
17 × 24 = **408** → labels = token_id ✅
This teaches the model how to reason rather than how to echo prompts.
LoRA Configuration
Unsloth handles the LoRA injection. The adapter targets the attention projection layers only:
| Parameter | Value |
|---|---|
| Rank (r) | 16 |
| Alpha | 32 |
| Target modules | q_proj, v_proj, k_proj, o_proj |
| Dropout | 0.05 |
| Max sequence length | 4096 |
| Quantization (training) | 4-bit NF4 |
| Optimizer | AdamW 8-bit |
| Epochs | 3 |
The base model runs in 4-bit NF4 during training, so the full pipeline fits in 8 GB GPU VRAM. The LoRA adapter itself is approximately 80 MB. After training, merge_and_unload() merges adapter weights into the base model for export.
GGUF Export and Quantization
The merged model passes through llama.cpp's converter and quantizer to produce a Q4_K_M file:
| Quantization | Size | RAM Needed | Speed |
|---|---|---|---|
| Q4_K_M | ~1.6 GB | 4 GB | ~12 tok/s on Pi 5 |
| Q5_K_M | ~1.96 GB | 4 GB | slightly slower |
| Q8_0 | ~2.89 GB | 6 GB | best quality |
Q4_K_M hits the practical sweet spot. It runs on a Raspberry Pi 5, any Android phone with 4 GB RAM, and Apple M1 Macs.
What the Reasoning Output Looks Like
Input: Why does ice float on water?
<think>
Water molecules form hydrogen bonds. In ice they arrange into a
hexagonal lattice — more space between molecules than liquid water.
Ice density = 0.917 g/cm³ vs liquid water 1.0 g/cm³ → floats.
</think>
Ice floats because it is less dense (0.917 g/cm³) than liquid water
(1.0 g/cm³). The hexagonal hydrogen-bond lattice in ice creates more
space between molecules than the compact liquid structure.
The <think> block is auditable. You can verify the reasoning steps before trusting the conclusion.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a knowledge distillation pipeline that adds DeepSeek-R1-style chain-of-thought reasoning to Llama 3.2 3B using Unsloth and LoRA. Use response-only training: mask all user turn tokens with labels=-100 so gradients only flow through assistant response tokens, which includes the
reasoning block. LoRA config: rank 16, alpha 32, target q_proj/v_proj/k_proj/o_proj, dropout 0.05, 4-bit NF4 base model, AdamW 8-bit optimizer, 3 epochs. The full pipeline must fit in 8 GB GPU VRAM. After training, merge the adapter with merge_and_unload() and export to GGUF Q4_K_M targeting ~1.6 GB that runs at 12 tok/s on a Raspberry Pi 5 with 4 GB RAM. Include a demo.py dry run mode that completes in ~0.12s showing config, dataset validation, and GGUF size estimates without downloading any model."
NEO generates the project structure and core implementation from that. From there you iterate — ask it to add Q5_K_M and Q8_0 quantization export options with size and RAM requirement tables, add the llama.cpp inference example with the Llama 3.2 chat format prompt showing how to prime the <think> block, or add HuggingFace Hub push support configurable via HF_REPO_ID. Each request builds on what's already there.
To use the released model directly, download from HuggingFace and run with llama.cpp:
pip install huggingface_hub
huggingface-cli download daksh-neo/llama-3-2-3b-reasoning-sft --local-dir ./model
./llama-cli -m model/llama-3-2-3b-reasoning-sft-Q4_K_M.gguf \
-p "<|start_header_id|>user<|end_header_id|>
Why is the sky blue?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
<think>" -n 256
The model produces an auditable <think> reasoning trace before the final answer, running fully offline on any device with 4 GB RAM.
NEO built a distillation pipeline that gives a 3B model structured reasoning traces while keeping inference under 2 GB and fully offline. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor