

Kokoro 82M vs Supertonic 3 vs Inflect-Nano-v1: A Real CPU TTS Benchmark
This post continues our earlier Kokoro 82M vs Supertonic 3 CPU benchmark. Same harness and methodology. Now with Inflect-Nano-v1 added and every sample scored with UTMOS objective MOS.
A complete evaluation of three open-weight TTS models across speed, latency, throughput, and audio quality, run entirely on CPU, no GPU involved, with an objective MOS score for every sample.
What Changed From the First Benchmark
In our first post, we compared Kokoro 82M and Supertonic 3 on CPU with 4 configurations and 120 timed runs. Quality was assessed by listening to 24 WAV samples, with no objective score. On AMD EPYC 7763, the headline was: Supertonic at 5-step was the best production speed/quality tradeoff (mean RTF 0.313), Kokoro won on naturalness (RTF ~0.47-0.51), and Supertonic at 2-step was fast but robotic.
This update extends that same harness on Intel Xeon Platinum 8272CL:
| First benchmark | This update | |
|---|---|---|
| Models | Kokoro 82M + Supertonic 3 | + Inflect-Nano-v1 (4.6M params) |
| Configurations | 4 | 5 |
| Timed runs | 120 | 150 |
| Quality scoring | Subjective listening notes | UTMOS objective MOS on every sample |
| Audio samples | 24 WAV files | 30 WAV files |
| Key speed shift | Supertonic 5-step RTF 0.313 | Supertonic 5-step RTF 0.195 (faster on this CPU) |
| New finding | n/a | Inflect-Nano is 2nd fastest overall (RTF 0.133) but buzzy by ear and capped at ~15s output |
The core verdict from the first post still holds: do not ship Supertonic 2-step, and Kokoro still wins on quality. Adding Inflect-Nano and UTMOS changes where each model lands on the speed/quality chart, and surfaces a hard output cap that raw throughput numbers would hide.
There are a lot of TTS benchmarks floating around that test on high-end hardware, cherry-pick favorable configurations, or only report one metric. This one tries to be more honest. We ran Kokoro 82M, Supertonic 3, and Inflect-Nano-v1 head-to-head on a CPU, measured everything that actually matters for a production decision, scored the audio quality with an objective neural MOS model, and listened to the outputs.
The short version: the fastest configuration is not the one you should ship, and the smallest model in the field punches well above its weight.
The Models
Kokoro 82M is a StyleTTS2-inspired model with 82 million parameters. It was released under Apache 2.0 (weights included), which is rare for a model of this quality. It outputs 24kHz audio and has two deployment paths: a native PyTorch pipeline via the hexgrad/Kokoro-82M HuggingFace repo, and an ONNX version from onnx-community/Kokoro-82M-v1.0-ONNX. At the time of its release it ranked first on the HuggingFace TTS Arena leaderboard.
Supertonic 3 is a newer model from Supertone with roughly 99 million parameters. Its architecture uses a Vector Estimator flow-matching backbone, which means the number of inference steps is a tunable parameter at runtime via total_steps. Lower steps = faster but lower quality. It supports 31 languages and outputs 44.1kHz audio. The license is OpenRAIL-M, which has some commercial use restrictions.
Inflect-Nano-v1 (owensong/Inflect-Nano-v1) is the new entrant and the outlier: a tiny 4.63M-parameter model, about 18× smaller than Kokoro and 21× smaller than Supertonic. It pairs a compact FastSpeech-style acoustic model (3.47M params) with a Snake-activation HiFi-GAN vocoder (1.17M params), outputs 24kHz audio, and is Apache-2.0. It ships only as a HuggingFace git repo (no pip package) and exposes a single English male voice. It uses a g2p_en grapheme-to-phoneme frontend rather than espeak. There were no published speed or quality benchmarks for it, so we made some.
What We Measured
The benchmark ran 5 configurations:
- Supertonic-3 at
total_steps=2(speed mode) - Supertonic-3 at
total_steps=5(default quality) - Kokoro-82M via PyTorch CPU
- Kokoro-82M via ONNX Runtime CPU
- Inflect-Nano-v1 via PyTorch CPU
Each configuration was tested across 6 text lengths: tiny (12 chars), short (59), medium (196), long (483), paragraph (851), and extended (1712 characters). Every cell got 5 timed repetitions after one discarded warmup run. That is 150 total timed runs.
The primary metric is RTF (Real-Time Factor): wall-clock synthesis time divided by the duration of the audio produced. RTF below 1.0 means the model synthesizes faster than real-time. Lower is faster.
We also recorded wall-clock latency in seconds and throughput in characters per second. For audio quality, we scored every sample with an objective MOS predictor. See How audio quality was scored (UTMOS) below.
How audio quality was scored (UTMOS)
MOS (Mean Opinion Score) is the standard way to rate synthesized speech. In a listening test, humans score each clip on a 1-5 naturalness scale (1 = bad/robotic, 5 = excellent/natural).
UTMOS (UTokyo Mean Opinion Score) is a neural model that predicts those human ratings from audio alone, so you can score many clips without running a listener panel. We used the utmos22_strong checkpoint (loaded via torch.hub in mos_eval.py).
What it does in this benchmark:
- After synthesis, we save one WAV per configuration per text length (30 files total).
mos_eval.pypasses each WAV through UTMOS and records a predicted MOS for that clip.- We report the mean score per configuration in the tables below. Higher = more natural-sounding, according to the model.
How to read the numbers in this post:
| UTMOS range | What it tends to mean in our results |
|---|---|
| ~4.4+ | Clearly usable, natural-sounding (Kokoro, Supertonic 5-step) |
| ~3-3.5 | Mid-range on paper; listen before trusting (Inflect-Nano over-rated here) |
| ~1.5 or below | Robotic, hard to understand (Supertonic 2-step) |
What it is not: a replacement for listening. UTMOS correlates well at the extremes but can be too generous to small HiFi-GAN vocoders that sound clean yet mechanical. We still listened to every embedded sample and call out where the score disagrees with our ears (see Inflect-Nano below).
Hardware: Intel Xeon Platinum 8272CL, 4 cores available, 15.6GB RAM, no GPU. CUDA_VISIBLE_DEVICES was set to empty for all runs. ONNX sessions were forced to CPUExecutionProvider.
The Headline
| Config | Mean RTF | vs Real-Time | Mean MOS (UTMOS) | Params |
|---|---|---|---|---|
| Supertonic-3 (2-step) | 0.112 | 8.9× | 1.57 | ~99M |
| Inflect-Nano-v1 | 0.133 | 7.5× | 3.48† | 4.6M |
| Supertonic-3 (5-step) | 0.195 | 5.1× | 4.38 | ~99M |
| Kokoro-82M (PyTorch) | 0.535 | 1.9× | 4.45 | 82M |
| Kokoro-82M (ONNX) | 0.564 | 1.8× | 4.44 | 82M |
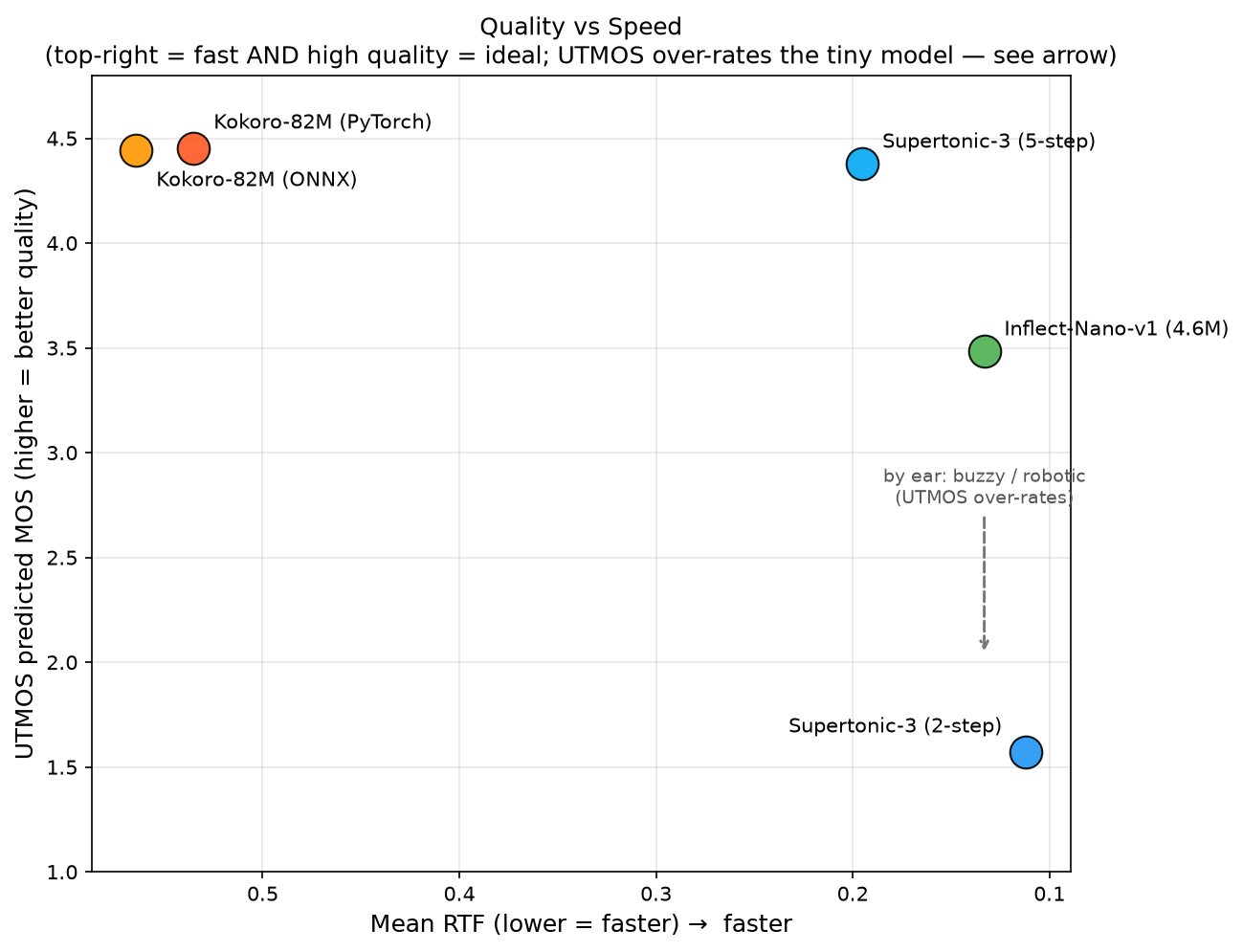
Quality (UTMOS MOS) against speed (mean RTF) (results/charts/quality_vs_speed.png). Faster is to the right; higher is better. The ideal corner is top-right. Supertonic-2step is fastest but bottom-of-the-barrel on quality; Kokoro is top-left (best quality, slowest); Supertonic-5step lands in usable territory. Note Inflect-Nano's 3.48 is plotted as-measured, but UTMOS over-rates it: by ear it is robotic (see below), so its real-quality position is lower than the dot suggests.
The single most important thing this chart shows: speed and quality are not the same axis, and the fastest config (Supertonic 2-step) is the worst-sounding by a wide margin. The objective MOS confirms what your ears tell you, with one exception: it over-rates the tiny Inflect-Nano (†), which sounds robotic despite its mid-range 3.48. More on that below.
The Numbers
RTF by Configuration and Text Length
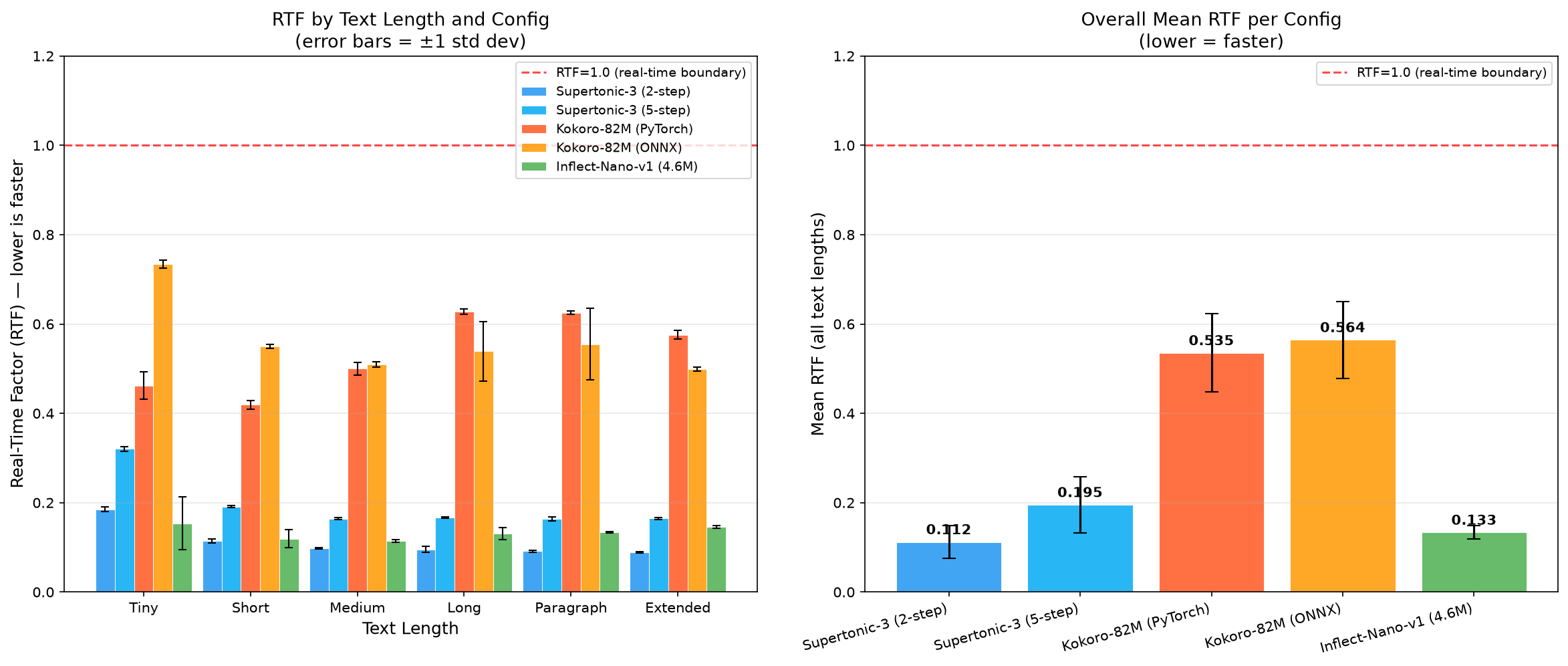
Mean RTF per configuration across all text lengths (results/charts/rtf_comparison.png). Lower is faster. All five configs run below RTF 1.0 (the real-time boundary).
| Config | Tiny | Short | Medium | Long | Paragraph | Extended | Mean |
|---|---|---|---|---|---|---|---|
| Supertonic-3 (2-step) | 0.185 | 0.114 | 0.097 | 0.095 | 0.091 | 0.088 | 0.112 |
| Supertonic-3 (5-step) | 0.321 | 0.191 | 0.164 | 0.166 | 0.164 | 0.165 | 0.195 |
| Kokoro-82M (PyTorch) | 0.462 | 0.419 | 0.500 | 0.628 | 0.625 | 0.576 | 0.535 |
| Kokoro-82M (ONNX) | 0.734 | 0.550 | 0.509 | 0.539 | 0.555 | 0.499 | 0.564 |
| Inflect-Nano-v1 | 0.154 | 0.120 | 0.114 | 0.131† | 0.134† | 0.146† | 0.133 |
Both Supertonic configs and Inflect-Nano sit far below RTF 0.2. Kokoro is the slowest of the three families on this CPU, hovering around RTF 0.5-0.6, and its RTF actually rises on longer inputs (0.46 → 0.63) rather than amortizing down the way the others do.
Note: Values marked † for Inflect-Nano reflect partial synthesis: the model truncates inputs longer than ~15s of audio. See the caveat below.
Wall-Clock Latency (seconds)
| Config | Tiny | Short | Medium | Long | Paragraph | Extended |
|---|---|---|---|---|---|---|
| Supertonic-3 (2-step) | 0.26s | 0.49s | 1.33s | 3.25s | 5.70s | 10.65s |
| Supertonic-3 (5-step) | 0.45s | 0.81s | 2.24s | 5.67s | 10.23s | 19.85s |
| Kokoro-82M (PyTorch) | 0.71s | 1.70s | 6.26s | 19.06s | 33.11s | 63.66s |
| Kokoro-82M (ONNX) | 0.69s | 1.92s | 6.08s | 16.55s | 29.05s | 51.90s |
| Inflect-Nano-v1 | 0.13s | 0.37s | 1.07s | 1.96s† | 2.01s† | 2.18s† |
Throughput (chars/sec)
| Config | Tiny | Short | Medium | Long | Paragraph | Extended |
|---|---|---|---|---|---|---|
| Supertonic-3 (2-step) | 46.5 | 121.7 | 147.5 | 149.3 | 149.3 | 160.8 |
| Supertonic-3 (5-step) | 26.9 | 72.7 | 87.4 | 85.2 | 83.2 | 86.2 |
| Kokoro-82M (PyTorch) | 17.1 | 34.8 | 31.3 | 25.3 | 25.7 | 26.9 |
| Kokoro-82M (ONNX) | 17.4 | 30.7 | 32.2 | 29.5 | 29.8 | 33.0 |
| Inflect-Nano-v1 | 104.7 | 162.2 | 182.9 | 248.8† | 424.5† | 784.6† |
Note: Inflect-Nano's throughput at long text lengths looks enormous because it stops generating after ~15s of audio regardless of how much text you give it. Those chars/sec figures are not real synthesis rates.
Audio Quality: UTMOS Predicted MOS (higher = more natural)
| Config | Tiny | Short | Medium | Long | Paragraph | Extended | Mean |
|---|---|---|---|---|---|---|---|
| Supertonic-3 (2-step) | 1.32 | 2.35 | 1.58 | 1.45 | 1.36 | 1.35 | 1.57 |
| Supertonic-3 (5-step) | 4.18 | 4.47 | 4.51 | 4.52 | 4.48 | 4.12 | 4.38 |
| Kokoro-82M (PyTorch) | 4.05 | 4.51 | 4.55 | 4.54 | 4.53 | 4.53 | 4.45 |
| Kokoro-82M (ONNX) | 4.04 | 4.51 | 4.54 | 4.55 | 4.52 | 4.49 | 4.44 |
| Inflect-Nano-v1 | 3.02 | 4.15 | 3.90 | 3.45 | 3.01 | 3.37 | 3.48 |
In our results, UTMOS tracks listening well at the extremes: Supertonic-2step's "robotic" output scores 1.57, while Kokoro and Supertonic-5step cluster around 4.4, but it is too generous to Inflect-Nano. Its 3.48 suggests "middle of the pack," yet to the ear Inflect-Nano is buzzy and robotic (see below). This is a known UTMOS failure mode: it rewards small HiFi-GAN vocoders for being clean even when they are not natural. Read Inflect-Nano's 3.48 as an optimistic upper bound, not a usability verdict.
The Tiny-Model Story: Inflect-Nano-v1
The most surprising result in the whole benchmark is what a 4.6M-parameter model can do. Inflect-Nano-v1 is the second-fastest configuration overall (RTF 0.133, 7.5× real-time), behind only Supertonic's quality-destroying 2-step mode, and it does this with under 5% of Kokoro's parameter count.
But it is not high-fidelity. On its UTMOS score (3.48) it looks mid-pack, and it is genuinely more intelligible than Supertonic-2step, but a careful listen tells a blunter story: the voice is buzzy and robotic, with a metallic vocoder texture and flat, monotone prosody. It is clearly synthetic in a way Kokoro and Supertonic-5step are not. So the honest framing is narrow: if you are choosing purely on a maximum-speed budget, Inflect-Nano is a more intelligible option than Supertonic-2step at the same latency, not a natural-sounding one. Don't let its 3.48 UTMOS (which over-rates small vocoders) read as "good."
The catch: a hard ~15-second output cap
There is one critical limitation you must know about. Inflect-Nano-v1's acoustic model is configured with max_frames = 1400, which caps synthesis at ~14.93 seconds of audio no matter how long the input text is. Feed it a 1700-character essay and it renders the first ~15 seconds and silently drops the rest.
You can see this directly in the audio durations: for the long, paragraph, and extended inputs, Inflect-Nano produces an identical 14.93s of audio, while every other model scales to 30-120s. That means its RTF and throughput on those three rows are inflated: it is doing far less work than the models it is being compared against. The honest comparison for Inflect-Nano is the tiny/short/medium rows, where the full text fits inside the cap.
For long-form synthesis (audiobooks, documents) you would need to split text into sub-15-second chunks yourself before feeding it in. For short, interactive utterances (chatbot replies, voice-assistant responses, notifications), the cap rarely bites, and this is exactly where a 4.6M-param model that runs at 7.5× real-time is compelling.
Audio Quality: Where the Story Changes
RTF numbers alone would make Supertonic 2-step the obvious choice. But the MOS scores and our ears tell a more complicated story.
The text used for the short samples below is the classic pangram: "The quick brown fox jumps over the lazy dog."
Supertonic-3 at 2-step sounds robotic (MOS 1.57). Words blur together and some are difficult to make out. This is not a bug: it is a fundamental property of flow-matching models. Fewer denoising steps means less waveform refinement. The RTF of 0.112 is impressive on paper, but the output is not something you would put in front of a user.
Supertonic-3 (2-step), short text:
Supertonic-3 at 5-step (MOS 4.38) is a different story: clearly intelligible, fully audible, and usable. It lacks some of the warmth and natural prosody of Kokoro, but it is not robotic. If latency is your primary constraint and you can accept slightly flat delivery, this is a reasonable choice.
Supertonic-3 (5-step), short text:
Kokoro 82M (both PyTorch and ONNX, MOS ~4.45) produces human-like speech. The prosody is natural, the pacing feels right, and it does not sound like a TTS system in the way older models do. The PyTorch and ONNX variants are perceptually indistinguishable; their MOS scores match to two decimals.
Kokoro-82M (PyTorch), short text:
Kokoro-82M (ONNX), short text:
Inflect-Nano-v1 (UTMOS 3.48 overall) is a single male voice that is buzzy and robotic to the ear: a metallic vocoder texture and flat prosody, despite the mid-range metric score. It is more intelligible than Supertonic-2step, but it does not approach Kokoro or Supertonic-5step. Impressive that a sub-5-megabyte model is intelligible at all; just don't expect natural.
Inflect-Nano-v1, short text:
The quality gap is clearer on longer text. Here are the medium samples (196 chars), within Inflect-Nano's length cap, so a fair comparison:
Supertonic-3 (2-step), medium text:
Inflect-Nano-v1, medium text:
Kokoro-82M (PyTorch), medium text:
The Combined Picture
| Config | Mean RTF | MOS | Params | Practical Verdict |
|---|---|---|---|---|
| Supertonic-3 (2-step) | 0.112 | 1.57 | ~99M | Prototyping only (robotic) |
| Inflect-Nano-v1 | 0.133 | 3.48† | 4.6M | Tiny + fast, but buzzy/robotic; short utterances only; ~15s cap |
| Supertonic-3 (5-step) | 0.195 | 4.38 | ~99M | Latency-critical, quality-acceptable |
| Kokoro-82M (PyTorch) | 0.535 | 4.45 | 82M | Quality-first, PyTorch stack |
| Kokoro-82M (ONNX) | 0.564 | 4.44 | 82M | Quality-first, lightweight deploy |
A few takeaways:
- If audio quality matters, Kokoro 82M wins (MOS ~4.45). It is the slowest of the three families on this CPU, but the output is human-like, and it is Apache 2.0, which matters for commercial use.
- For the best speed/quality balance, Supertonic-3 at 5-step (MOS 4.38 at 5.1× real-time) is hard to beat: usable quality at a fraction of Kokoro's latency.
- Inflect-Nano-v1 is an impressive engineering demo more than a production voice: 4.6M params at 7.5× real-time is remarkable, and it is more intelligible than Supertonic-2step, but it is buzzy and robotic by ear, and it caps output at ~15 seconds. Reach for it only when footprint and speed dominate and voice quality is genuinely secondary.
- Supertonic-3 at 2-step is a prototyping tool, not a production config. Its MOS of 1.57 is the objective version of "it sounds robotic."
- UTMOS over-rated the tiny model. Its 3.48 for Inflect-Nano disagreed with every human listen (buzzy/robotic). Objective MOS is a useful signal at the extremes, but on small HiFi-GAN vocoders it can flatter clean-but-mechanical output. Worth remembering before trusting a single quality number.
† Inflect-Nano's 3.48 UTMOS over-rates its perceived quality; by ear it is buzzy/robotic.
How This Benchmark Was Run
This evaluation was produced by Neo, an autonomous AI engineering agent, from a single prompt: benchmark these three CPU TTS models across speed, latency, throughput, and audio quality.
From that prompt, Neo:
- Researched each model's architecture and API, including that Inflect-Nano-v1 ships only as a HuggingFace git repo with an importable
synthesize()rather than a pip package - Measured all five configurations on a single machine for an apples-to-apples comparison
- Wrote an
InflectNanoRunnerfor the existing harness and fixed two real-world integration snags along the way: the model's LFS weights andnumba/nltkdata were undeclared dependencies, andkokoro-onnx 0.5.0feeds the v1.0 ONNX model'sspeedinput asint32(it expectsfloat) and returns 2-D audio that broke long-text concatenation. Both patched at the session boundary without editing the installed package - Added
mos_eval.py, scoring every sample with UTMOS (utmos22_strong) loaded from torch.hub - Discovered and reported Inflect-Nano's ~15s output cap rather than letting its inflated long-form numbers stand unqualified
- Regenerated the report, charts, and this writeup
These are the kinds of things that would slow down a manual setup. Neo handled them autonomously as part of the run.
Replicate or Extend This Benchmark
The full benchmark code, raw results, charts, and audio samples are in the benchmark repository.
git clone https://github.com/gauravvij/kokoro-tts-vs-supertonic-3-tts.git
cd kokoro-tts-vs-supertonic-3-tts
The key files:
benchmark.py: the full harness, runs all 150 timed experiments (5 configs)mos_eval.py: scores every saved WAV with UTMOS, writesresults/mos_results.csvreport.py: reads the CSVs, generates the markdown report and chartsresults/raw_results.csv: raw timing data, 150 rowsresults/mos_results.csv: per-sample MOS scoresresults/benchmark_report.md: the full reportresults/charts/: RTF comparison, latency vs length, and quality-vs-speed chartsresults/audio_samples/: 30 WAV files for quality listening
To re-run from scratch you need Python 3.10+, espeak-ng installed system-wide, and the Python packages: supertonic, kokoro, kokoro-onnx, onnxruntime, soundfile, matplotlib, pandas, numpy, torch, torchaudio, numba, plus g2p_en/transformers and the Inflect-Nano repo (git clone https://huggingface.co/owensong/Inflect-Nano-v1 models/Inflect-Nano-v1). The Kokoro ONNX model files and voices binary go in models/ (see the download commands in the README).
What You Can Build on Top of This
Extend the benchmark:
"Add Coqui XTTS-v2 as a sixth configuration and re-run the comparison"
"Wrap Inflect-Nano-v1 in a sentence-chunking layer so it can synthesize long-form text past its 15-second cap, then re-benchmark its true long-input RTF"
"Swap UTMOS for DNSMOS or a human MOS panel and compare the rankings"
Build something with the models:
"Build a FastAPI TTS service that uses Kokoro 82M ONNX for synthesis, with a /synthesize endpoint that accepts text and returns a WAV file"
"Build a low-latency voice-assistant reply pipeline on Inflect-Nano-v1 for sub-15-second utterances, falling back to Kokoro for longer text"
Neo works as an autonomous agent in VS Code or Cursor via the Neo extension. You give it a goal, it plans the implementation, writes the code, runs it, and iterates until it works. The benchmark in this repo is a good starting point for any of the above.
Files in This Repo
benchmark.py # Full benchmark harness (150 timed runs, 5 configs)
mos_eval.py # UTMOS quality scoring
report.py # Report and chart generator
results/
raw_results.csv # 150 rows of raw timing data
mos_results.csv # 30 rows of per-sample MOS
benchmark_report.md # Full analysis report
charts/
rtf_comparison.png # Grouped bar chart by config
latency_vs_length.png # Line chart across text lengths
quality_vs_speed.png # MOS vs RTF scatter
audio_samples/ # 30 WAV files (1 per config x text length)
Hardware: Intel Xeon Platinum 8272CL, 4 cores, 15.6GB RAM, no GPU. Python 3.12.3. supertonic 1.3.1, kokoro 0.9.4, kokoro-onnx 0.5.0, onnxruntime 1.27.0, torch 2.12.1, UTMOS utmos22_strong.
Evaluation harness and all result files: https://github.com/gauravvij/kokoro-tts-vs-supertonic-3-tts
Built by Neo
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor