
Integration-Centric vs Capability-Centric: Two Approaches to Enterprise AI Platform Engineering
Opening Hook
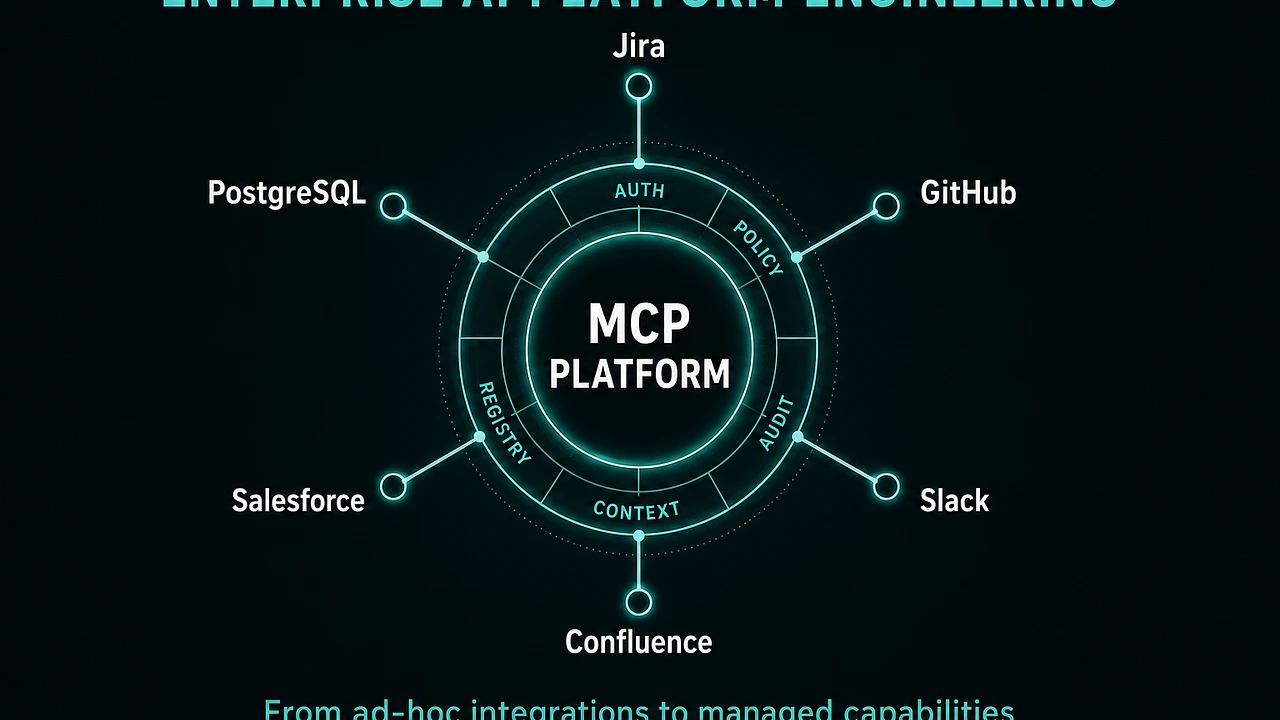
Enterprises today run hundreds of internal tools, databases, APIs, and SaaS products. AI agents that need to act across these systems face challenges in discovering what capabilities are available, ensuring those calls comply with policy, managing context within LLM limits, and orchestrating multi-step workflows without brittle integrations.
The Experiment
We asked two independent teams to solve the same problem: build a production-grade AI platform that lets agents discover, call, and orchestrate capabilities across enterprise systems via the Model Context Protocol (MCP). The platform had to support tool discovery, context management, multi-system orchestration, governance, security, permissions, observability, multi-agent coordination, and scale to tens of thousands of employees.
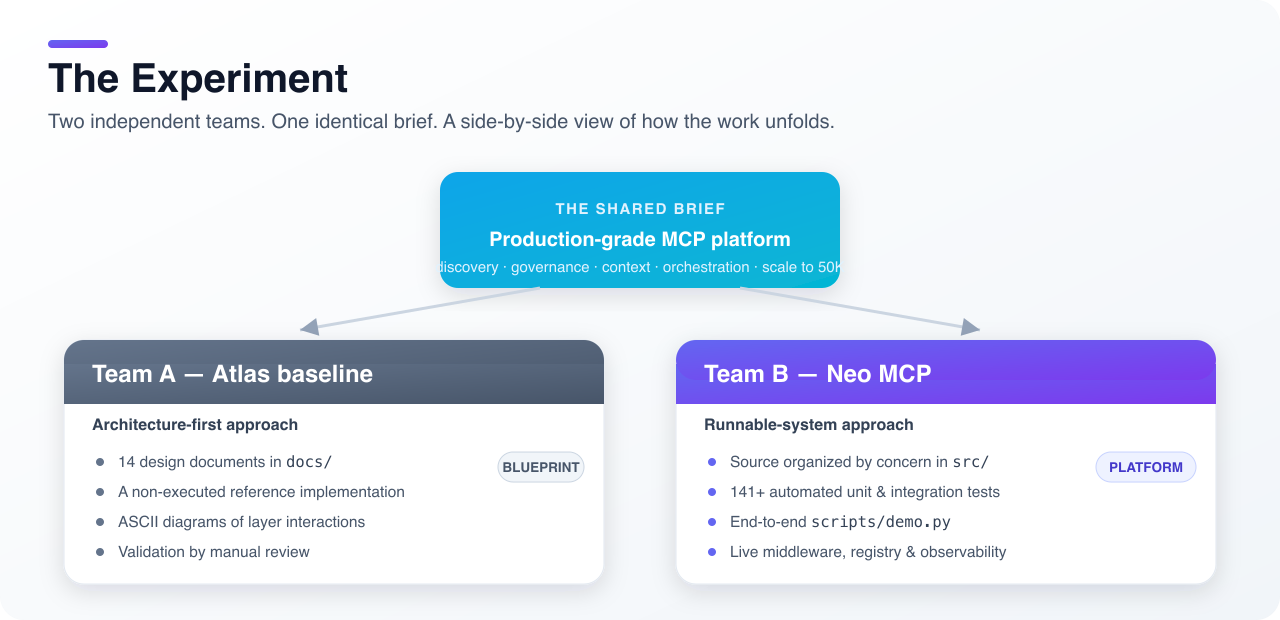
Team A followed a conventional architecture-first approach (later referred to as the Atlas baseline). Team B used Neo MCP as the foundation. Both teams delivered complete solutions, giving us a side-by-side view of the outcomes.
What We Expected
Given the scope, we anticipated architecture diagrams, component specifications, and perhaps a reference implementation showing how the pieces would fit together.
What Actually Happened
Team A (Atlas baseline) produced a comprehensive set of design documents and a reference implementation:
- 14 detailed design documents in
docs/covering enterprise topology, MCP topology, agent runtime, context engineering, tool discovery, governance, permissions, security, reliability, observability, marketplace, multi-agent coordination, deployment, and production readiness. - A reference implementation in
reference-implementation/illustrating a gateway, registry, context engine, policy engine, orchestrator, and agent SDK. - ASCII-style diagrams in each document showing layer interactions.
Team B (Neo MCP) focused on building a runnable system:
- Source code in
src/neo_mcp/organized by concern (gateway, context, governance, marketplace, multiagent, orchestrator, permissions, observability, reliability). - 141+ automated unit and integration tests under
tests/exercising the registry, policy engine, context manager, marketplace, orchestrator, and demo workflows. - An end-to-end demo script (
scripts/demo.py) that: registers six MCP servers (Jira, GitHub, Slack, Confluence, Salesforce, PostgreSQL), runs a multi-step Project Phoenix investigation workflow, demonstrates policy enforcement (allow/deny/require_approval), shows multi-agent delegation, and prints observability outputs (metrics, traces, audit logs, cost). - Actual middleware stack in
src/neo_mcp/api/main.py: every request passes through authentication → policy evaluation → injection detection → audit logging → cost tracking before reaching the router. - A Server Registry with convenience methods (
add_server,remove_server,get_server_status,list_all_tools) and a Marketplace Registry for publishing/discovering tools, workflows, and agents with versioning and approval states. - Context Manager (
src/neo_mcp/context/manager.py) that enforces a token budget, compresses older messages, prioritizes by query relevance, and maintains three-tier memory (working, episodic, semantic). - Reliability components: circuit breaker, retry handler with exponential backoff, fallback handler, and health checker.
- Observability stack: metrics collector, tracer, audit logger, cost tracker, and dashboard renderer, all wired into the middleware pipeline.
- A production readiness assessment (
docs/production_readiness.md) identifying gaps for hardening (deployment automation, incident response runbooks, disaster recovery).
In short, Team A delivered a comprehensive blueprint; Team B delivered a runnable platform that could be tested, operated, and observed.
Comparison of Key Artifacts
| Capability | Atlas (Baseline) | Neo MCP |
|---|---|---|
| Registry | Documented in design docs | Implemented ServerRegistry with CRUD methods |
| Governance | Proposed policy layers in docs | Executed policy engine in middleware pipeline |
| Context Management | Specified token budgets & compression | Enforced token budget, compression, prioritization in ContextManager |
| Marketplace | Designed as a concept | Operational MarketplaceRegistry with publish/discover/versioning |
| Observability | Architecture diagram | Instrumented middleware (metrics, traces, audit, cost) |
| Testing | Limited to reference-implementation snippets | 141+ automated unit/integration tests |
| Demo / Validation | No end-to-end executable demo | scripts/demo.py runs full stack end-to-end |

Visual Architecture
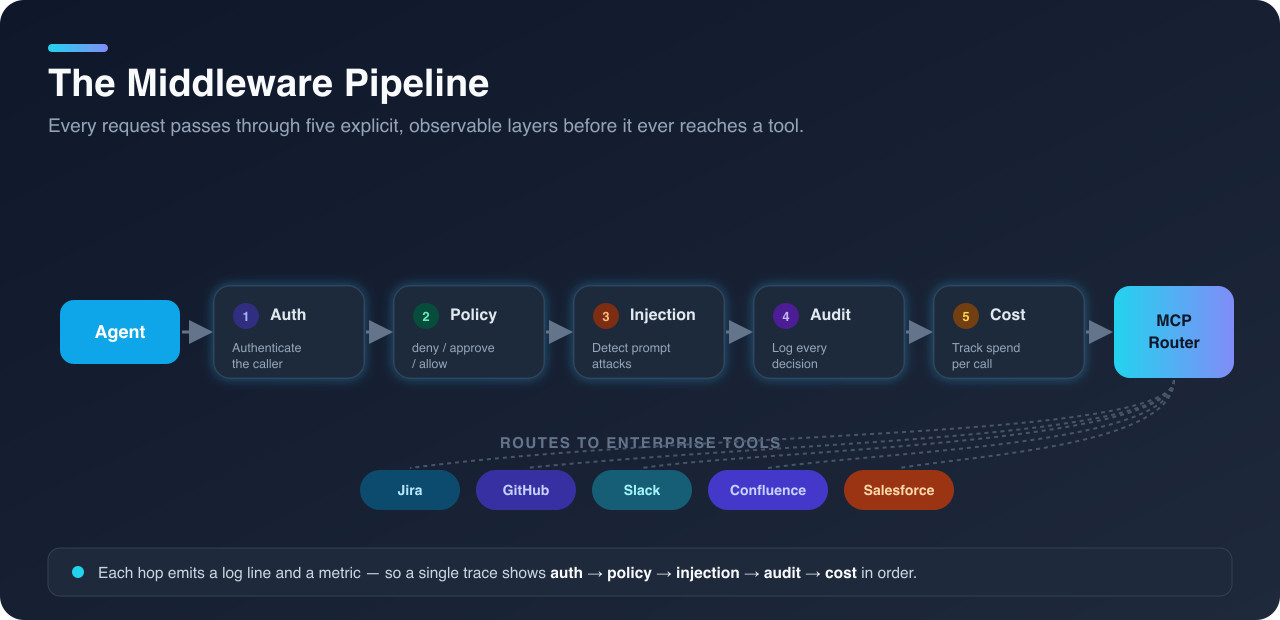
Middleware Pipeline (request flow)
Agent
↓
Authentication
↓
Policy Engine
↓
Injection Detection
↓
Audit Logging
↓
Cost Tracking
↓
MCP Router
↓
Enterprise Tool (Jira, GitHub, Slack, etc.)
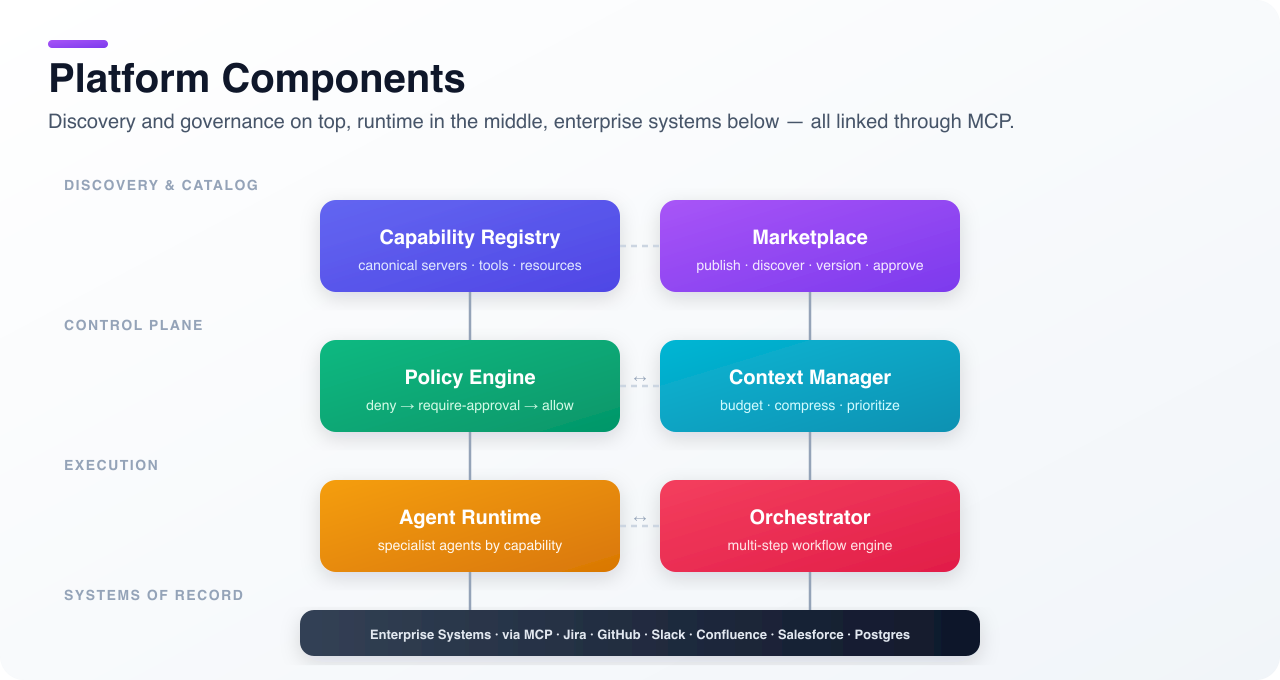
Platform Components
Capability Registry Marketplace
↓ ↓
Policy Engine ←→ Context Manager
↓ ↓
Agent Runtime ←→ Orchestrator
↓
Enterprise Systems (via MCP Servers)
Workflow Transformations
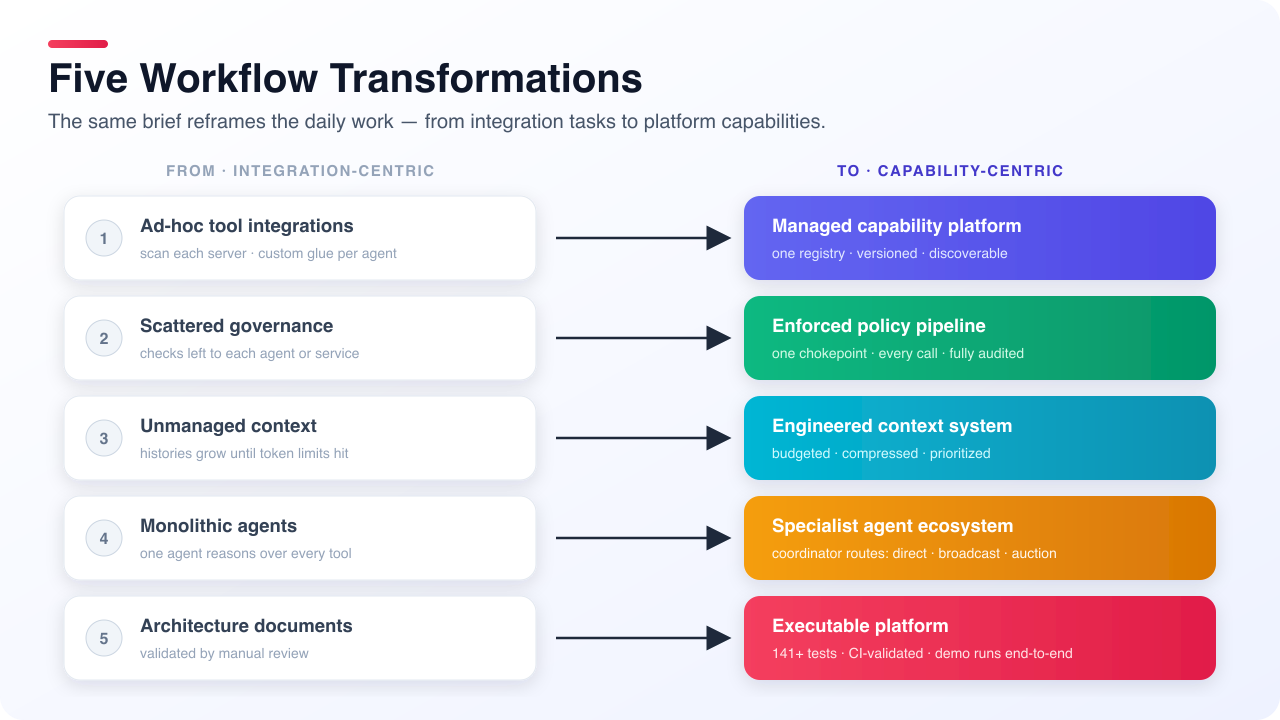
1. From Tool Integrations to Managed Capability Platforms
Baseline Approach: The Atlas reference implementation showed each MCP server as a standalone FastMCP app; agents discovered tools by scanning each server individually or via ad-hoc configuration. There was no central catalog of what tools existed across servers, nor a standard way to version or deprecate them.
Neo MCP Approach: The Server Registry holds a canonical list of servers, their tools, and resources. Tools are versioned via the Marketplace Registry, which tracks approval state and lets teams search by keyword or tag. The demo script registers six servers and then lists all tools via the registry's list_all_tools() method.
Engineering Implication
- Operationally: Teams no longer need to write custom discovery logic for each agent; they query a single registry.
- Organizationally: Ownership of the capability catalog shifts to a platform team, reducing duplication across squads.
- Architecturally: The registry becomes a contract boundary; changes to a tool's interface are propagated through versioning in the marketplace, enabling safe evolution.
2. From Scattered Governance to Enforced Policy Pipelines
Baseline Approach: The Atlas documents described governance layers, but the reference implementation left policy checks to individual agents or services. There was no centralized enforcement point, making it hard to guarantee that every tool call was evaluated against the same rules.
Neo MCP Approach: The policy engine sits in the middleware pipeline and evaluates every tool call before it reaches the MCP router. DENY policies are checked first, then REQUIRE_APPROVAL (which creates an approval request), then ALLOW policies. All decisions are logged to the audit trail. The demo script shows a denied call when a tool requires approval and the approval workflow is triggered.
Engineering Implication
- Operationally: Governance becomes systematic and observable; compliance teams can trace a denied call to the exact policy that blocked it.
- Organizationally: Policy authoring is centralized; updates go through a single change-control process instead of being scattered across agent repositories.
- Architecturally: The middleware stack makes governance a cross-cutting concern that is easy to audit and modify without touching agent code.
3. From Unmanaged Context to Engineered Context Systems
Baseline Approach: The context engineering document described token budgets and compression, but the reference implementation did not enforce limits or prioritize content. Agents would accumulate full conversation histories and tool outputs until hitting token limits, with no mechanism to discard stale information.
Neo MCP Approach: The Context Manager measures token usage, compresses messages when the budget is exceeded, prioritizes context by query relevance and recency, and stores summaries in episodic and semantic tiers. The demo script prints context statistics showing how many messages were compressed and how many memory items were retrieved for a given query.
Engineering Implication
- Operationally: Long-running workflows stay within LLM limits without losing important information; token waste is reduced, lowering cost and latency.
- Organizationally: Teams can tune compression and prioritization heuristics centrally, rather than each agent implementing its own truncation logic.
- Architecturally: Context becomes a pluggable service; different strategies (summarization, filtering, external knowledge injection) can be swapped without changing the agent runtime.
4. From Monolithic Agents to Specialist Agent Ecosystems
Baseline Approach: The reference implementation featured a generic agent SDK that left specialization to the developer. Agents tended to be monolithic, attempting to reason over and act on every tool, leading to bloated, hard-to-maintain code.
Neo MCP Approach: Agents are implemented as domain-specific classes (JiraAgent, GitHubAgent, etc.) with clearly defined capabilities. The MultiAgentCoordinator discovers agents by capability, selects a delegation pattern (direct, broadcast, auction) based on the number of matches, and aggregates results. The demo script shows a workflow delegating to multiple specialist agents and combining their outputs.
Engineering Implication
- Operationally: Separation of concern improves reliability and lets teams scale agent types independently. Complex workflows can combine multiple specialists without bloating a single agent's codebase.
- Organizationally: Ownership of agent capabilities aligns with domain teams (e.g., the Jira agent is owned by the Jira platform team).
- Architecturally: The coordinator abstracts delegation patterns, making it easy to add new agent types or change routing logic without rewriting workflows.
5. From Architecture Documents to Executable Platforms
Baseline Approach: The team authored design documents and a reference implementation that was not exercised by automated tests. Validation relied on manual review and diagram inspection.
Neo MCP Approach: Every major component is covered by unit tests; the demo script runs the full stack end-to-end. Changes are validated by the CI pipeline before they are merged. The test suite exercises failure cases (e.g., policy denial, registry lookup miss) and asserts expected outputs.
Engineering Implication
- Operationally: Fast feedback loops reveal integration bugs early; engineers spend less time speculating about interactions and more time fixing observable failures.
- Organizationally: A testable platform encourages a culture of continuous integration and delivery; release confidence improves.
- Architecturally: The system's behavior is known, not guessed, which reduces risk when evolving the platform under load.
What Neo MCP Doesn't Solve

- Added latency: Each middleware hop adds ~0.5-2ms in our demo. For latency-sensitive loops (e.g., high-frequency trading alerts), teams may need to bypass certain checks after a formal risk assessment.
- Operational complexity: Running separate services for registry, policy engine, context manager, and marketplace increases failure domains. Teams must invest in monitoring, alerting, and runbooks for each; the production readiness assessment calls out missing incident-response runbooks.
- Learning curve: Engineers must learn Rego-/Cedar-like policy syntax, understand the context manager's compression tradeoffs, and use the marketplace CLI to publish and discover capabilities. This adds onboarding time for new hires.
- Over-engineering for small teams: A two-person startup may not need a full policy engine or three-tier context; a simpler MCP gateway with ad-hoc discovery could be sufficient and faster to deploy.
- Data-plane performance: The current Server Registry is process-local; horizontal scaling requires externalizing state (e.g., to Redis Cluster), which introduces consistency considerations and potential split-brain scenarios.
- Context fidelity loss: The summarization step in the context manager may discard fine-grained details that some workflows need; developers must tune compression thresholds and may need to bypass the context manager for certain calls.
- Policy performance: As the number of policies grows, linear evaluation in the policy engine could become a bottleneck; production deployments would need indexing or caching strategies.
- Marketplace trust: While the marketplace tracks approval state, it doesn't inherently guarantee the quality or security of published capabilities; additional scanning or attestation would be needed for high-assurance environments.
Final Thoughts
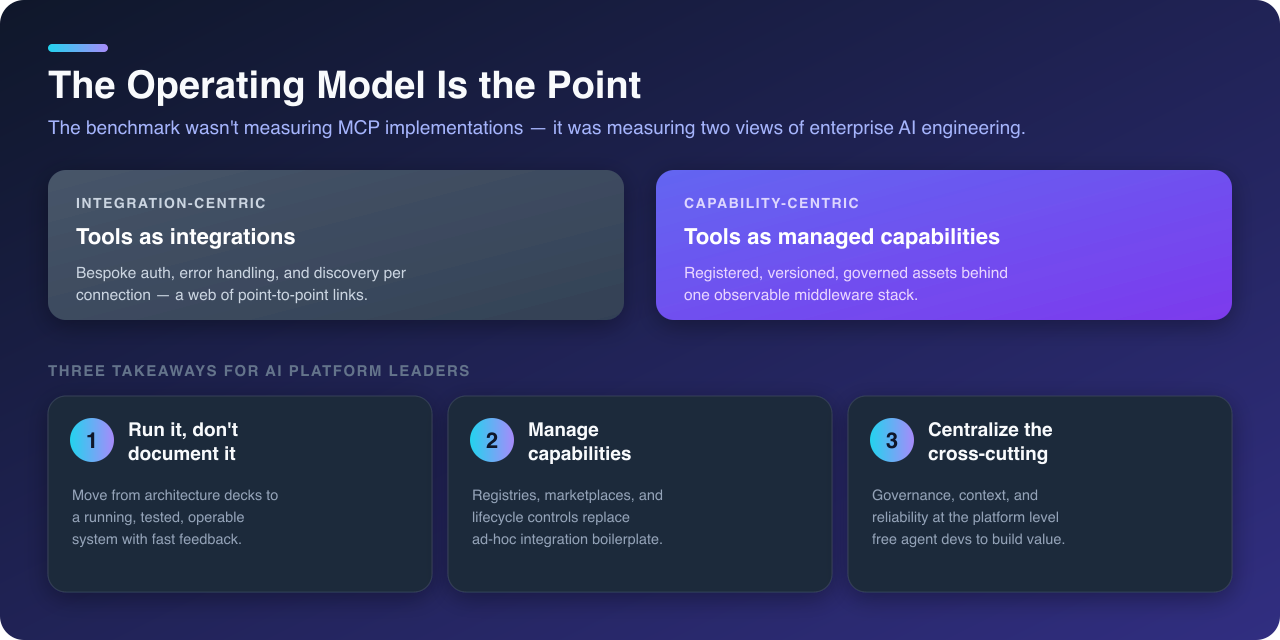
The benchmark wasn't really measuring MCP implementations.
It was measuring two different views of enterprise AI engineering.
One treated tools as integrations: each connection required bespoke auth, error handling, and discovery logic, leading to a web of point-to-point links that was hard to govern and observe.
The other treated tools as managed platform capabilities: capabilities were registered, versioned, discoverable, and governed in a centralized marketplace, with every call passing through an observable middleware stack that enforced policy, tracked cost, and preserved context.
The most important difference wasn't code volume, architecture quality, or feature count.
It was the operating model that emerged from that choice: a shift from writing integration code for each tool to investing in a shared platform where capabilities are first-class services, governed by explicit contracts, and observable at every step.
For anyone leading AI infrastructure, the takeaway is clear: treat capabilities as managed platform assets, invest in the contracts and observability that make them operable at scale, and let agent developers focus on delivering value through specialized agents and workflows. That's how you build AI that can safely and effectively navigate the enterprise landscape.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor