

EmbedAudit: A CLI Tool for Auditing Semantic Embedding Spaces
The Problem
Embeddings fail quietly. A model's vector representations can look reasonable in aggregate while hiding structural problems that hurt retrieval quality, clustering accuracy, or downstream classification performance. When retrieval results seem semantically wrong or a fine-tuned model underperforms relative to baseline, the problem is frequently in the vector space — but most teams have no systematic way to inspect it.
NEO built EmbedAudit — a CLI tool that automates that inspection. Feed it text, vocabulary, CSV data, or pre-computed .npy files, and it runs a systematic audit: dimensionality reduction, clustering, anomaly detection, and a structured report with recommendations.
The Five Semantic Checks
The core of EmbedAudit is a set of five semantic checks that run on every audit. These aren't generic statistical tests. They target the specific failure modes that matter for NLP embedding quality.
Outlier Detection identifies tokens or phrases whose vector position is far from any meaningful cluster. Outliers sometimes represent legitimate edge cases, but they often indicate tokenization artifacts, training data gaps, or vocabulary items the model hasn't seen in useful context.
Boundary Ambiguity finds regions where clusters overlap in ways that suggest semantic confusion. If "bank" (financial) and "bank" (riverbank) land in the same neighborhood, your embedding space has a polysemy problem that will surface as retrieval noise.
Isolated Token Detection flags tokens that are semantically isolated: present in the vocabulary but not meaningfully connected to surrounding concept clusters. These often cause unexpected misses in retrieval systems.
Polarity Mismatch Detection checks whether tokens with opposite semantic polarity are landing too close together. Antonyms should be distant in a well-calibrated embedding space. When they're not, sentiment and contrast tasks become unreliable.
Global Collapse Detection identifies whether the overall embedding space has collapsed into a tight cluster, which happens when models overfit or when the training distribution is too narrow. A collapsed embedding space looks fine by individual pair similarity metrics but fails badly on any task requiring semantic discrimination.
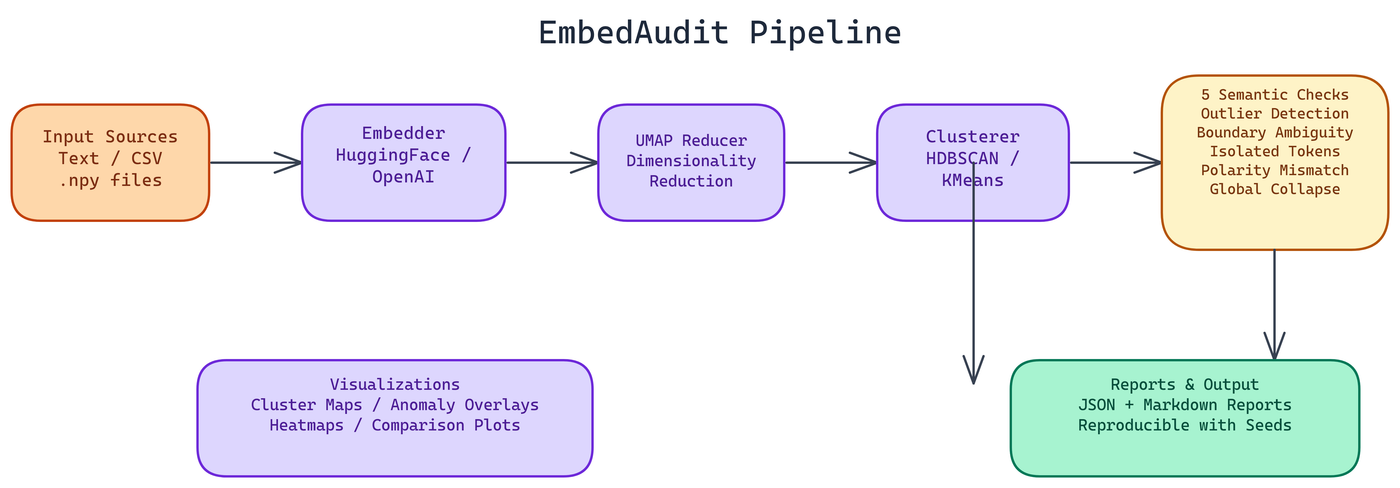
The Pipeline
The processing flow is: Input → Embedder → Reducer → Clusterer → Auditor → Reporter/Visualizer → Output.
Each stage is swappable. The embedder supports HuggingFace local models by default, with OpenAI and OpenRouter compatibility for remote inference. The reducer uses UMAP, which preserves local structure better than PCA for high-dimensional embedding spaces. The clusterer supports HDBSCAN, KMeans, or both with automatic parameter selection based on dataset size.
HDBSCAN is the more informative choice for most embedding audits because it doesn't require specifying the number of clusters in advance. It finds density-based clusters of varying sizes and explicitly marks low-density points as noise, which is exactly what you want when looking for structural anomalies.
Visualizations
EmbedAudit generates several visualization types. Cluster maps show the full embedding space with UMAP projection and cluster coloring. Anomaly overlays mark the flagged tokens from each of the five checks directly on the cluster map. Heatmaps show pairwise similarity distributions across clusters. Comparison plots let you view two embedding configurations side by side, which is useful when evaluating fine-tuning impact or comparing model variants.
All visualizations are designed to be useful without requiring deep familiarity with the underlying math. A product manager reviewing retrieval quality can look at an anomaly overlay and understand why certain queries are returning unexpected results.
Reports and Reproducibility
Reports come in JSON and Markdown formats. The JSON report is structured for downstream processing. The Markdown report is designed for human readers, with an executive summary, per-check findings, and a prioritized list of recommendations.
Reproducibility is handled through configurable seeds and metadata tracking. Every audit run captures the embedding model version, clustering parameters, UMAP configuration, and the random seed used. If you run the same audit six months later after a model update and the results differ, you have a precise record of what changed.
Configuration Options
EmbedAudit accepts configuration via CLI flags, .env files, or a .embedaudit.yaml file. CLI flags take precedence, which makes it easy to override defaults for specific runs without changing the base configuration. This matters for teams that run regular audits as part of a deployment pipeline and need the flexibility to test variations quickly.
For large corpora, optimization options reduce memory usage by processing embeddings in batches and sampling for the visualization step. For small vocabulary analysis, the default settings handle everything without tuning.
When to Run an Embedding Audit
The short answer: before deploying any system that depends on embedding quality, and again after any significant model update or fine-tuning run.
The longer answer: if you're seeing retrieval results that seem semantically wrong, if clustering on your data produces unstable or uninterpretable groups, or if a fine-tuned model is underperforming relative to a baseline, an embedding audit is often faster than debugging the downstream system. The problem is frequently in the vector space, not in the retrieval logic.
EmbedAudit makes that inspection fast and systematic. NEO built it because the same diagnostic steps were needed every time embedding quality issues arose. Automating those steps into a reproducible tool was the obvious move.
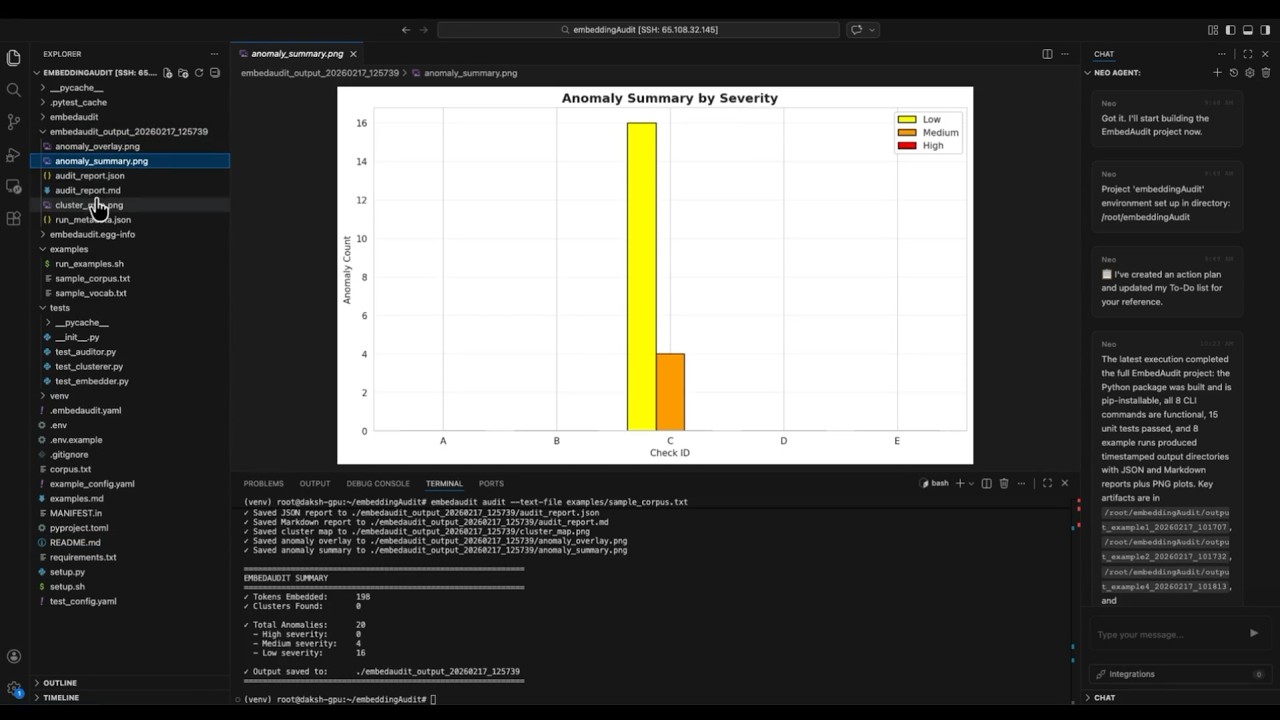
Watch It in Action
NEO put together a full CLI walkthrough showing EmbedAudit running on a real vocabulary set, from the initial audit command through to the UMAP cluster map and the final report output.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a Python CLI tool called EmbedAudit that audits semantic embedding spaces. It should accept text files, CSV files, vocabulary lists, or pre-computed .npy files as input, generate embeddings using a local HuggingFace model, reduce dimensions with UMAP, cluster with HDBSCAN, and run five targeted checks: outlier detection, boundary ambiguity, isolated token detection, polarity mismatch, and global collapse detection. Output a timestamped directory with a 2D cluster map, anomaly overlay, centroid heatmap, a structured JSON report, and a Markdown summary with prioritized recommendations. Support CLI flags, .env files, and a .embedaudit.yaml config file."
NEO generates the project structure and core implementation from that. From there you iterate — ask it to add OpenAI and OpenRouter embedding provider support, add side-by-side comparison plots for evaluating fine-tuning impact between two model variants, or add batch processing mode for large corpora that samples for the visualization step. Each request builds on what's already there.
To run the finished project:
git clone https://github.com/dakshjain-1616/Embedding-Evaluator
cd Embedding-Evaluator
pip install -e .
embedaudit audit --text-file corpus.txt
Point it at any text file and it runs the full five-check audit, producing a cluster map, anomaly overlay, and Markdown report in a timestamped output directory.
NEO built a semantic embedding audit tool where UMAP, HDBSCAN, and five targeted checks surface outliers, polarity mismatches, and global collapse before they silently degrade downstream retrieval quality. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor