

From Synthetic Data Generation to Dataset Engineering: What Changed When We Added Neo MCP
We compared two workflows for building an AI evaluation dataset: Claude Code alone, and Claude Code augmented with Neo MCP. The goal was not to declare a winner, but to understand how the workflow changes when generation is wrapped in a governed pipeline.
Both workflows targeted the same deliverable: a benchmark of real-world agent-failure scenarios across ten distinct failure categories, with typed provenance, no synthetic padding, and a consistent schema. Both used Claude Code as the underlying implementation engine. The difference was architectural. The first workflow used Claude Code interactively, guiding the model toward the deliverable in a single conversation. The second used Claude Code to implement a pre-specified pipeline, with the dataset produced as a reproducible, auditable artifact.
Two Dimensions of Dataset Quality
Before describing what changed, it helps to name the distinction that the comparison made visible.
When people say a dataset is "good," they usually mean one of two things. Generation quality covers lexical diversity, semantic richness, label accuracy, and realistic coverage of the scenario space. Engineering quality covers reproducibility, verifiability, provenance completeness, and operational reliability, the properties that determine whether a dataset can be maintained, audited, and rebuilt by someone who wasn't in the original conversation.
These dimensions are largely independent, and investing in one often comes at some cost to the other. The comparison below is, at its core, a study of how each workflow distributes effort across them.
Starting Point: Interactive Generation
For small datasets of a few dozen examples, prompting Claude Code interactively is entirely sufficient. The model reads source material, extracts structure, classifies intent, and writes output at scale. For a first pass or a focused experiment, this works.
The gaps emerge at production scale. Three issues recurred when we pushed toward a benchmark of hundreds of records across ten categories:
Reproducibility was social rather than technical. The dataset existed as the output of a specific conversation. Recreating it required preserving that conversation intact and using the same model version. Without fixed seeds, manifests, or per-phase content hashes, "we documented what we did" was the only guarantee.
Verification was bounded by what we thought to check. Checking for duplicates meant asking the model to grep for them. Near-duplicate detection, type-consistent provenance across all records, and adversarial corner cases required the engineer to enumerate them explicitly, and the list was easy to leave incomplete.
Scale strained the context window. Processing thousands of source records interactively required manual chunking and ad-hoc merging. Scripts got written anyway, they just weren't versioned, sequenced, or reproducible.
The model was not the bottleneck. The absence of a repeatable engineering layer around it was.
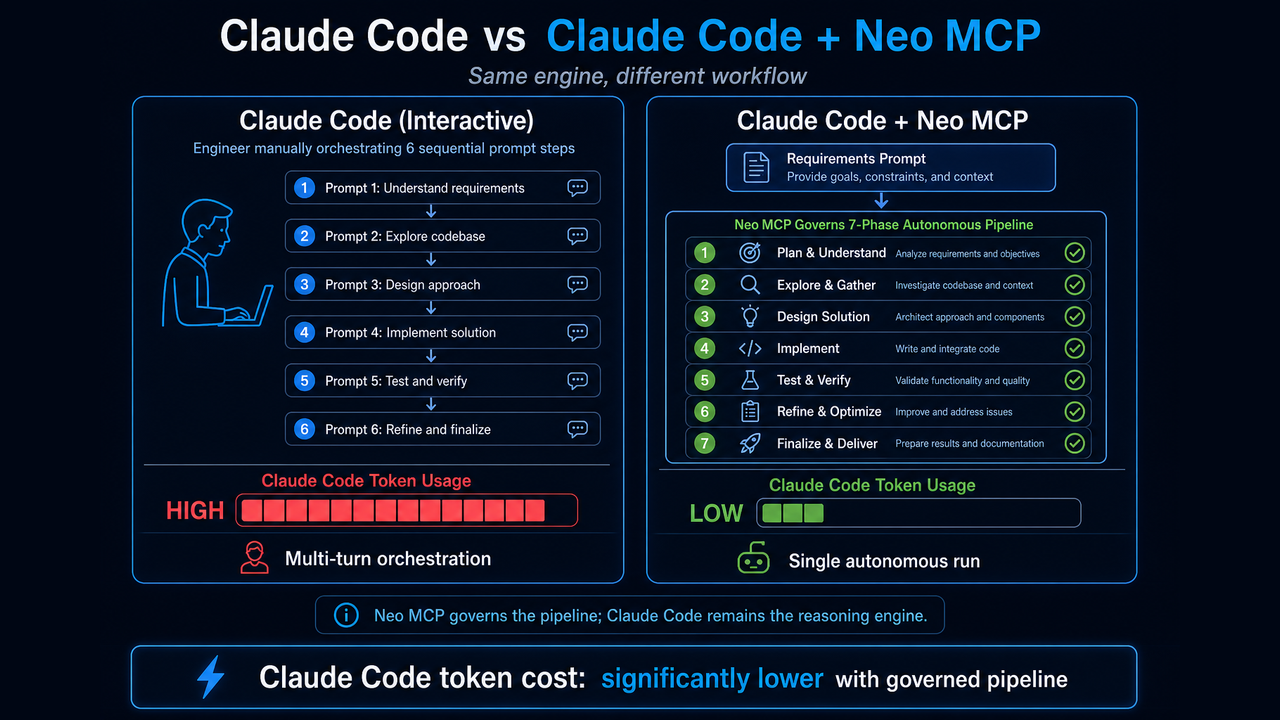 Claude Code token usage compared: interactive multi-turn orchestration versus Claude Code + Neo MCP single autonomous run
Claude Code token usage compared: interactive multi-turn orchestration versus Claude Code + Neo MCP single autonomous run
One Prompt. No Hand-Holding.
The most operationally significant difference between the two workflows was not a metric, it was the nature of the human involvement required.
Interactive Claude Code places the engineer in the role of orchestrator at every decision point. Each phase requires a prompt: collect this, check that output, apply this dedup logic, validate the schema, decide when to stop. Context management, chunking, and phase transitions are the engineer's ongoing responsibility. The quality of the output is directly coupled to the quality and continuity of the prompting session.
Claude Code + Neo MCP received a single requirements prompt (specifying the target categories, quality constraints, and schema) and autonomously determined what the pipeline needed to look like: which sources to collect from, how to handle deduplication, how to derive classifications from content, what the verification checks should cover, and when to stop rather than pad. No mid-run corrections. No step-by-step guidance. No re-prompting when the context window filled up.
This autonomy has a compounding effect on reproducibility. Because the decision-making is encoded in the pipeline itself rather than in an engineer's prompting session, anyone can re-run it and get the same result. There is no dependence on a specific engineer's knowledge of what was asked and in what order.
Both workflows bill Claude Code tokens. The interactive Claude Code workflow consumes significantly more Claude Code tokens at every phase transition, checking output, correcting course, re-stating context. The Claude Code + Neo MCP pipeline still runs on Claude Code, but executes to completion in a single run with far less back-and-forth overhead.
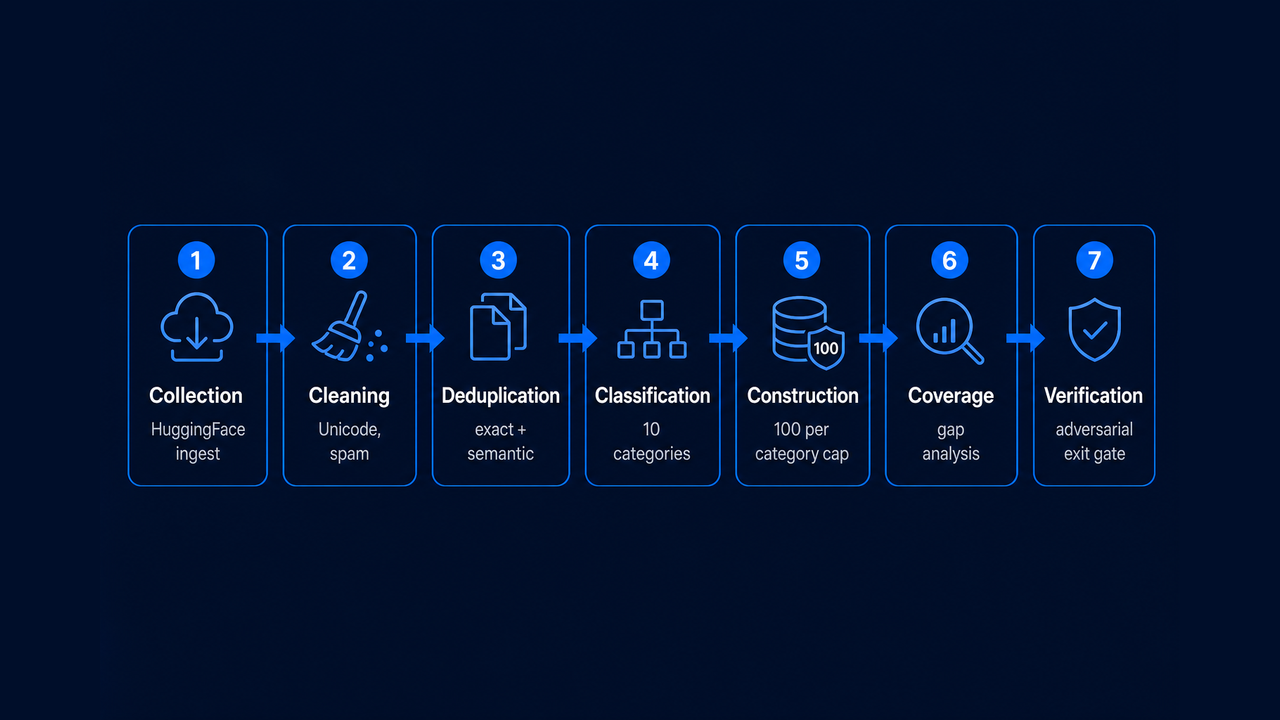 Seven-phase pipeline: Collection through Verification with governed exit gates
Seven-phase pipeline: Collection through Verification with governed exit gates
What Neo MCP Was Built to Fix
Neo MCP was designed by diagnosing the specific failure modes of unstructured LLM-based data generation and building explicit controls against each one. The resulting pipeline runs in seven phases:
Collection ingests from four HuggingFace datasets, applies a relevance gate (subreddit blocklist, non-English detection, technical-keyword minimum), and computes a content hash for each record before truncation, preserving integrity before any mutation occurs.
Cleaning applies Unicode normalization, whitespace handling, and spam removal across caps ratio, URL patterns, and repetitive characters.
Deduplication runs three layers in sequence: a content relevance filter, SHA-256 exact-match deduplication keyed on the raw query hash, and sentence-transformer near-duplicate filtering at cosine ≥ 0.85 using all-MiniLM-L6-v2 with greedy clustering, running on CPU, no GPU required.
Classification derives category, difficulty, root cause, and expected tools from record content using 10-category keyword scoring, 70+ root-cause regex patterns, and 40+ tool-extraction patterns, content-derived rather than template-stamped.
Construction selects up to 100 records per category, rebalances difficulty by within-category swaps, and assigns sequential IDs, all under a fixed seed (42) for deterministic output.
Coverage and gap analysis computes distribution reports directly from the final artifact, each carrying the dataset content hash so every number is traceable to its source.
Verification runs a ten-point adversarial exit gate. Terminal failure is reserved for hard structural violations; documented data gaps produce warnings, not failures.
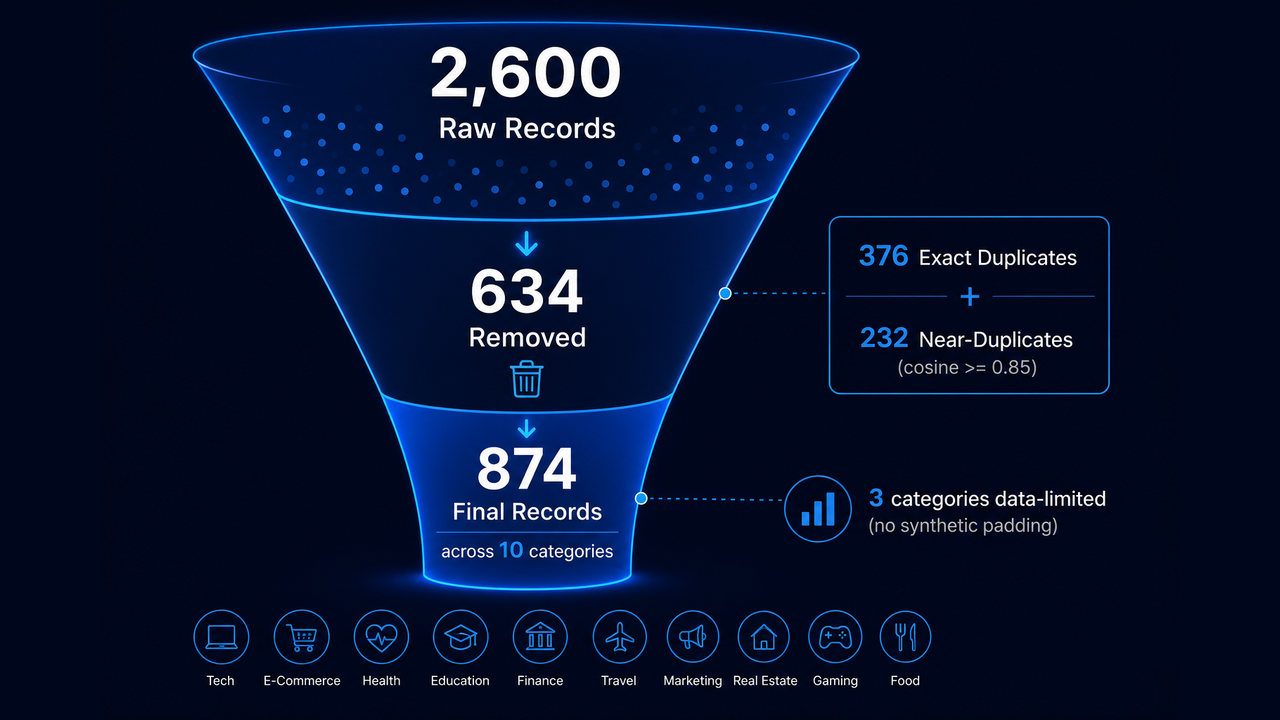 Data funnel: 2,600 raw records to 874 final after deduplication and category caps
Data funnel: 2,600 raw records to 874 final after deduplication and category caps
The Data Funnel
The pipeline processed 2,600 raw records. Deduplication removed 634, 376 exact matches and 232 near-duplicates. Construction selected from the remaining pool under per-category caps. The final dataset contained 874 records across ten categories.
The plan targeted 1,000 records at 100 per category. Three categories finished at 72, 72, and 30 records because the real-world source pools for those categories were exhausted before reaching the cap. Rather than pad to the target with synthetic records, the pipeline documented the ceilings and stopped. That decision is recorded in pipeline_config.json and gap_analysis.md. Choosing to surface real data scarcity rather than paper over it with fabrication is a deliberate design principle, not an unreported shortfall.
Key Design Decisions
Three decisions in the pipeline architecture account for most of the engineering quality gains.
Verifier Independence
The adversarial verifier (verify.py) is written as a completely separate artifact from the pipeline that builds the dataset. It does not share code, configuration, or assumptions with the construction scripts. This matters because a verifier written by the same system that built the dataset will naturally check for the things the builder already ensures, and miss the things it doesn't.
The verifier checks for the specific failure modes that plague unstructured generation: duplicate IDs, duplicate queries, near-duplicate semantic similarity, type-inconsistent provenance fields, null provenance, field type violations, difficulty imbalance, category underfill, synthetic record contamination, and content hash drift. These are adversarial checks against the builder's blind spots, not confirmations of what the builder intended to produce.
Deterministic Reproducibility
Fixed random seeds (42 for both random and numpy) are applied across all seven scripts. Package versions are documented in pipeline_config.json. A run_manifest.json records phase-level row counts and content hashes, creating a forward trace from raw source to final record that any operator can verify independently. The dataset can be rebuilt and the rebuild will be byte-identical.
This converts reproducibility from a social convention ("we documented what we did") into a technical invariant.
The Data-Limited Stop
When a category's real-world source pool runs dry before the per-category cap is reached, the pipeline documents the ceiling and stops. It does not generate synthetic padding to reach an arbitrary row target. The gap_analysis.md records which categories are data-limited and why. This means the benchmark reflects the actual distribution of available real-world data for each failure category, not a manufactured approximation of it.
Verification Results
The adversarial verifier passed all ten checks against the final 874-record dataset, with three documented warnings for the data-limited categories and an exit code of zero:
- Duplicate record IDs: zero
- Duplicate user queries: zero
- Near-duplicate cosine similarity ≥ 0.85: zero
source_tracetype consistency: 874/874 typed dictionaries- Null provenance fields: none
- Field type validation across ten required fields: pass
- Difficulty distribution within ±2% tolerance: pass
- Category balance: pass for seven categories, warnings for three documented data-limited categories
- Synthetic records: zero
- Content hash consistency against
run_manifest.json: pass
Every record carries a typed source_trace dictionary with six fields, source type, source ID, source name, URL, original dataset, and synthetic flag.
Independent Governance Assessment
An independent audit of the pipeline produced formal governance scores across five dimensions:
| Governance Dimension | Score |
|---|---|
| Auditability | 9/10 |
| Reproducibility | 8/10 |
| Lineage / Provenance | 8/10 |
| Maintainability | 7/10 |
| Operational Complexity | 7/10 |
The audit classified Neo MCP as a Dataset Management System, distinct from a generator because it includes lifecycle management, adversarial verification as a gated exit condition, a complete lineage chain from raw source to final record, and fixed-seed reproducibility controls. The audit noted that the lineage and auditability infrastructure was "unusually complete" relative to comparable pipelines at this scale.
Quantitative Summary
| Metric | Claude Code (interactive) | Claude Code + Neo MCP |
|---|---|---|
| Schema validity | 100% | 100% |
| Exact duplicates | 0 | 0 |
| Claude Code token usage | Higher (multi-turn orchestration) | Lower (single autonomous run) |
| Deterministic regeneration | No | Yes |
| Generation-time duplicate guard | No | Yes |
| Machine-readable audit scores | Limited | Yes |
On schema validity and exact duplicates both workflows achieved equivalent results. Both workflows consumed Claude Code tokens; the governed pipeline used significantly fewer because it eliminated multi-turn orchestration overhead. On reproducibility, in-pipeline duplicate detection, and machine-readable audit artifacts, Claude Code + Neo MCP delivered capabilities the interactive Claude Code workflow did not.
What the Combination Produced
It is worth being precise about the relationship between the two tools, because the efficiency gain comes specifically from the combination, not from either one alone.
Claude Code was the reasoning engine throughout. It wrote every script, designed the classification logic, determined what the verification checks should cover, and made the judgment calls that structured each phase. The intelligence behind the pipeline (what to collect, how to deduplicate, how to balance the dataset, when a record should be excluded) was Claude Code's.
Neo MCP provided the engineering discipline that gave that reasoning a repeatable, auditable form. It enforced the phase structure, the schema, the exit conditions, and the audit trail. It ensured that Claude Code's decisions were encoded into artifacts that any operator could inspect, re-run, and verify, not locked inside a conversation that only the original engineer could reconstruct.
The result was something neither produces alone. Claude Code without the pipeline structure produces high-quality output that is fragile at scale (hard to reproduce, hard to verify, and dependent on the engineer staying in the loop. A rigid pipeline without Claude Code's reasoning produces structure without intelligence) enforced phases but shallow decisions inside each one.
Together, Claude Code's reasoning was channeled through a governed engineering framework, and the output reflected both: a dataset that passed ten adversarial verification checks, carried full provenance on every record, and was produced autonomously from a single prompt with significantly lower Claude Code token usage than the interactive baseline. That is the efficiency gain, not one tool outperforming the other, but the two operating in their respective strengths simultaneously.
When This Pattern Fits
The pipeline investment pays off when the dataset is a maintained engineering asset rather than a one-time artifact. Specifically, it becomes the right choice when:
- The dataset will be rebuilt as sources are updated or categories are expanded
- The dataset will be shipped to external evaluators or partners who need to verify provenance independently
- The pipeline will be re-run by engineers who were not present for the original run
- The evaluation context requires an auditable chain from raw source to final record
For a single focused experiment where the engineer owns the full context and reproducibility is not a requirement, interactive generation remains faster and more semantically flexible. The governed pipeline trades iteration speed for operational reliability, that trade-off is worth making when the dataset has a lifecycle longer than a single project.
The strongest version of this pattern extends the classification layer with LLM-assisted reasoning inside the pipeline's phase structure, retaining reproducibility and auditability while raising the semantic ceiling above what a regex pattern set can achieve. That hybrid represents the natural next step for teams that need both dimensions of dataset quality at once.
Conclusion
The benchmark suggests that synthetic data quality has at least two dimensions: generation quality and engineering quality. Claude Code remained stronger on lexical diversity and tool realism, while Neo MCP strengthened reproducibility, validation, auditability, and operational simplicity. The right choice depends on whether the dataset is a one-time artifact or a maintained engineering asset.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor