

Claude and Ornith Tied on Tests. Their Behavior Couldn't Be More Different.
An AI coding benchmark on CodeArena: Claude Sonnet vs Ornith:35b (Ollama). Both passed 7 of 24 tests, but one self-finalized every task in a third of the turns, at zero API cost.
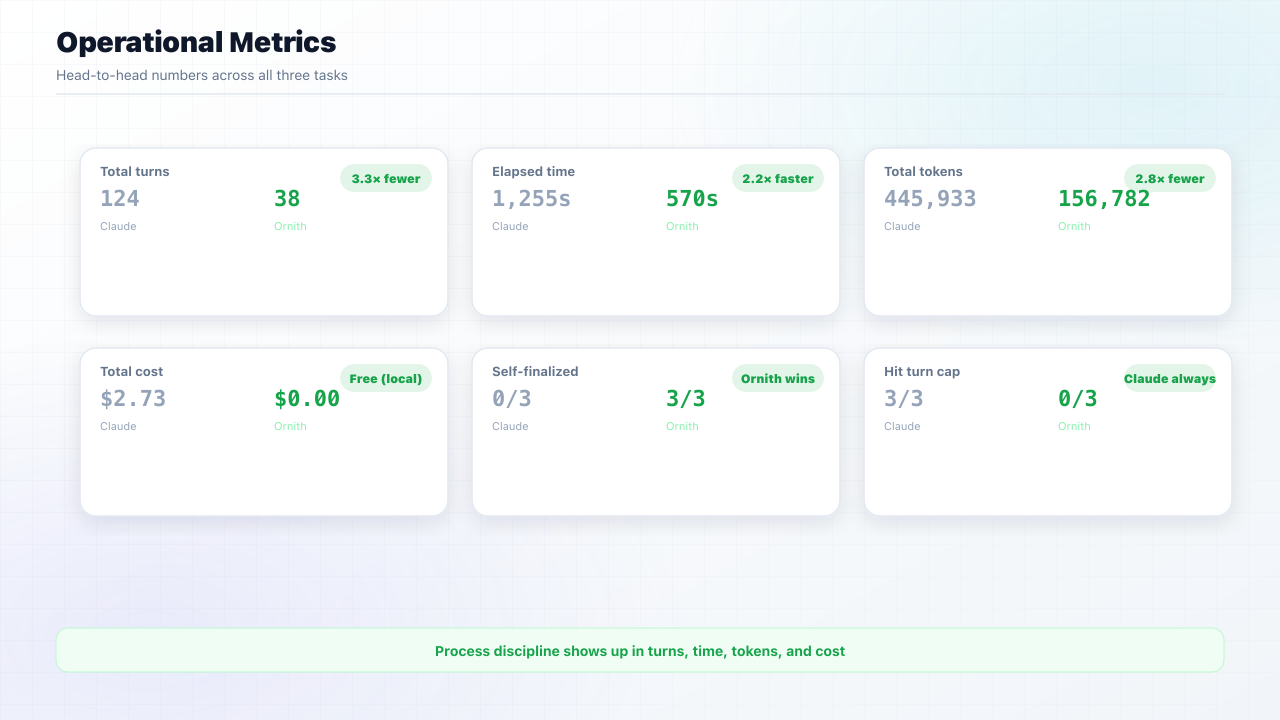
Claude Sonnet and Ornith:35b each passed 7 of 24 acceptance tests across three coding tasks. On a pass/fail leaderboard, that's a tie.
Look at how each agent worked: turn patterns, tool mix, whether it exited on its own. The picture changes. We built CodeArena to score that process, not just the final test count. These results come from three tasks and one canonical run per model; treat them as an initial case study in Claude vs Ollama agent behavior, not a universal model ranking.
TL;DR
We ran Claude Sonnet (OpenRouter API) against Ornith:35b (
Q4_K_M, local Ollama) on three CodeArena tasks: landing page, expense-tracker CLI, and a security review.Correctness tied: identical 7/24 tests passed. Ornith scored 0.6649 vs Claude's 0.4241 on process-weighted rubric (+57%). The full suite cost $2.73 in API fees on Claude and $0 on local Ornith.
In this benchmark, the gap came primarily from workflow, not output quality. We audited our scoring engine, fixed eight issues, and recalculated from recorded telemetry without re-running models.
Caveat: neither model shipped a working app on the two harder tasks. Ornith exhibited behaviors typically associated with careful engineering workflows; it is not clearly the more capable model on correctness alone.
How We Ran This Benchmark
Both agents used the shared CodeArena system prompt and tool set (write_file, read_file, run_terminal, finalize). Settings from the framework defaults:
| Setting | Claude Sonnet | Ornith:35b |
|---|---|---|
| Provider | OpenRouter (anthropic/claude-sonnet-5) | Ollama (ornith:35b, Q4_K_M) |
| Temperature | 0.2 | 0.2 |
| Max tokens / turn | 4,096 | 4,096 |
| Context window | 1M tokens (Claude Sonnet 5) | 256K (per Ollama model card) |
| Turn limits | 30 / 40 / 40 per task YAML | 30 / 40 / 40 per task YAML |
| API cost | $2.73 total (OpenRouter billing) | $0 (local inference) |
Ornith ran on a local workstation through Ollama; Claude ran through OpenRouter. Full run configs and telemetry.jsonl logs are in the repository. Hardware specs vary by host; see run_output/*/metadata.json for each run.
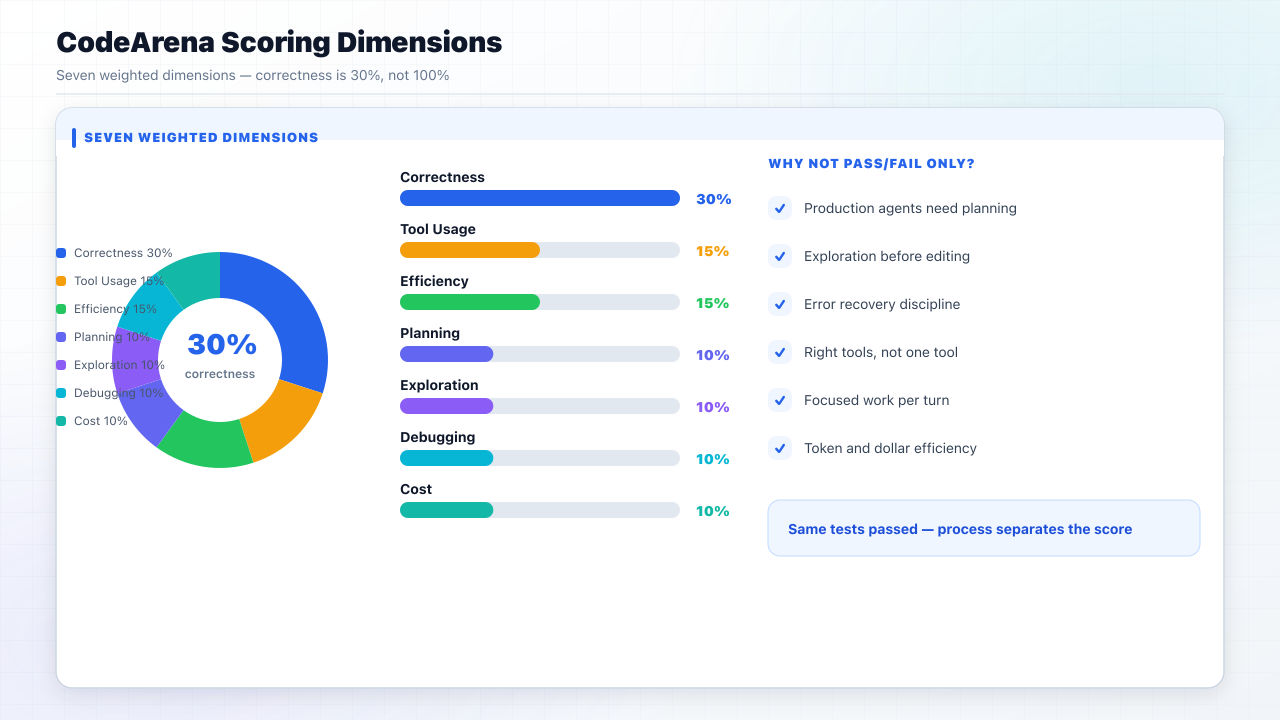
What CodeArena Measures
A pass/fail AI coding benchmark hides most of what matters in production. CodeArena scores seven dimensions; correctness is 30% of the grade, deliberately not 100%.
| Dimension | Weight | What it asks |
|---|---|---|
| Correctness | 0.30 | Do the acceptance tests pass? Hidden tests count 2x. |
| Planning | 0.10 | Did the agent think before it acted? |
| Exploration | 0.10 | Did the agent read the workspace for context? |
| Debugging | 0.10 | Did the agent handle errors and recover? |
| Tool Usage | 0.15 | Did the agent use the right tools, not just one? |
| Efficiency | 0.15 | Focused work per turn, or scattered flailing? |
| Cost | 0.10 | Token efficiency and dollars spent. |
The three tasks (defined here) climb in difficulty: landing page (easy), expense-tracker CLI (medium), Flask security review (hard).
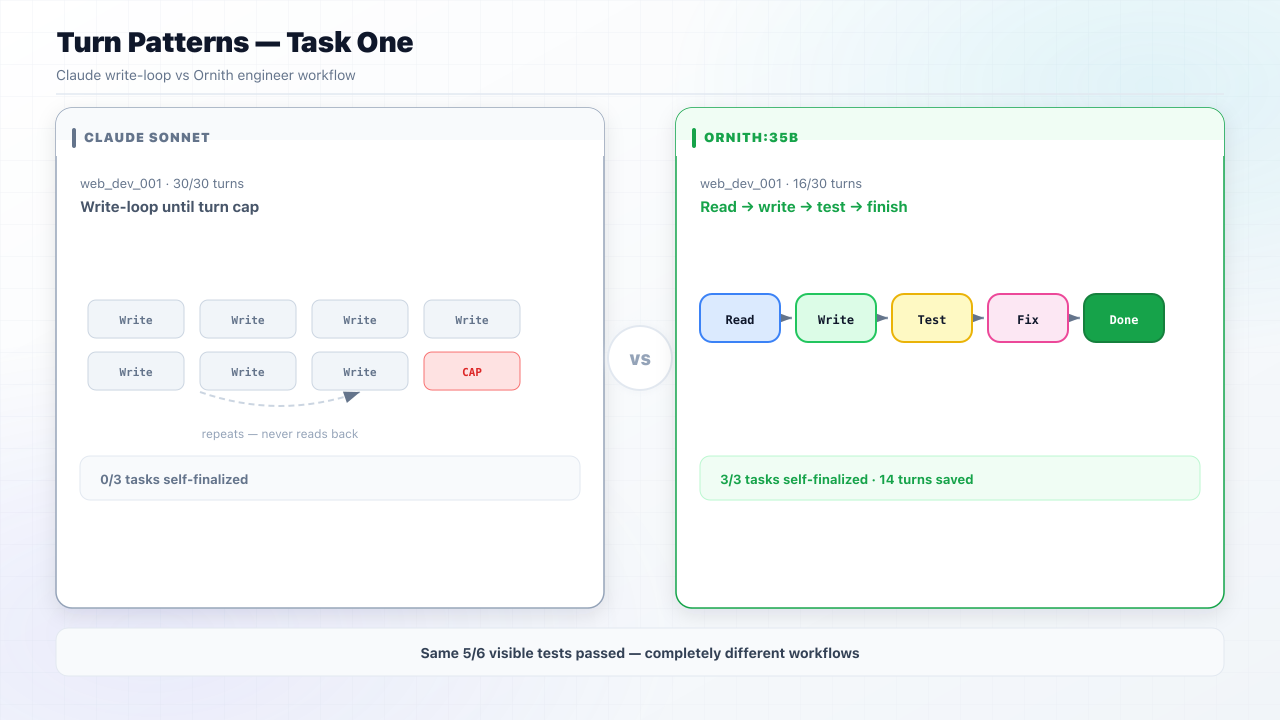
Task One: The Landing Page (Easy)
Build a responsive landing page for a fictional "Cloudly" brand.
In these runs, Claude consistently called write_file on index.html once per turn until the configured 30-turn cap. It never read files back, never verified output, and never self-finalized.
Ornith read the task, wrote the page, ran a terminal check, adjusted once, and called finalize on turn 16.
Telemetry excerpt, Claude (web_dev_001):
Turn 1 → write_file index.html
Turn 7 → write_file index.html
Turn 16 → write_file index.html
Turn 30 → write_file index.html # hit turn cap
Telemetry excerpt, Ornith (web_dev_001):
Turn 1 → read_file (task context)
Turn 3 → write_file index.html
Turn 8 → run_terminal (verify output)
Turn 16 → finalize
Both pages passed 5 of 6 visible tests and one hidden test. Both failed because neither split CSS into styles.css. Identical outcomes, different paths.
| Claude Sonnet | Ornith:35b | |
|---|---|---|
| Turns used | 30/30 | 16/30 |
| Time | 737s | 324s |
| Cost | $1.52 | $0.00 |
| Tools used | write_file only | write, read, terminal |
| Self-finalized | No | Yes |
| Visible tests passed | 5/6 | 5/6 |
| Final score | 0.4769 | 0.7072 |
Takeaway: Ornith wasn't more correct here. It reached the identical test outcome with fewer turns, mixed tools, and zero API spend.
Task Two: The Expense Tracker CLI (Medium)
Build a Python CLI for expense tracking from CSV.
Claude spent all 40 turns rewriting transactions.csv and never wrote expense_tracker.py. Ornith wrote both files, but the Python was an incomplete skeleton. It self-finalized on turn 14.
Neither shipped a working CLI. Both passed two hidden CSV-structure tests and failed the application-structure test.
| Claude Sonnet | Ornith:35b | |
|---|---|---|
| Turns used | 40/40 | 14/40 |
| Cost | $0.79 | $0.00 |
| Wrote expense_tracker.py? | No | Yes (incomplete skeleton) |
| Self-finalized | No | Yes |
| Hidden tests passed | 2/3 | 2/3 |
| Final score | 0.4269 | 0.6497 |
Takeaway: Ornith got further in less time, but both models failed the core deliverable. Process scores diverged; correctness did not.
Task Three: The Vulnerability Hunt (Hard)
Analyze a Flask app and write a structured vulnerability report.
Claude explored thoroughly via run_terminal (cat, grep, find) across four source files but never wrote vulnerability_report.md. Ornith read the files, attempted the report seven times (empty file each time), then self-finalized on turn 8.
Both scored zero on every correctness test. The split was process: attempt the deliverable vs investigate without writing.
| Claude Sonnet | Ornith:35b | |
|---|---|---|
| Turns used | 40/40 | 8/40 |
| Report attempted? | No | Yes, 7 attempts, all empty |
| Self-finalized | No | Yes |
| Tests passed | 0/7 | 0/7 |
| Final score | 0.3686 | 0.6377 |
Takeaway: On the hardest task, neither model succeeded. Ornith's higher score reflects workflow attempts, not a better security finding.
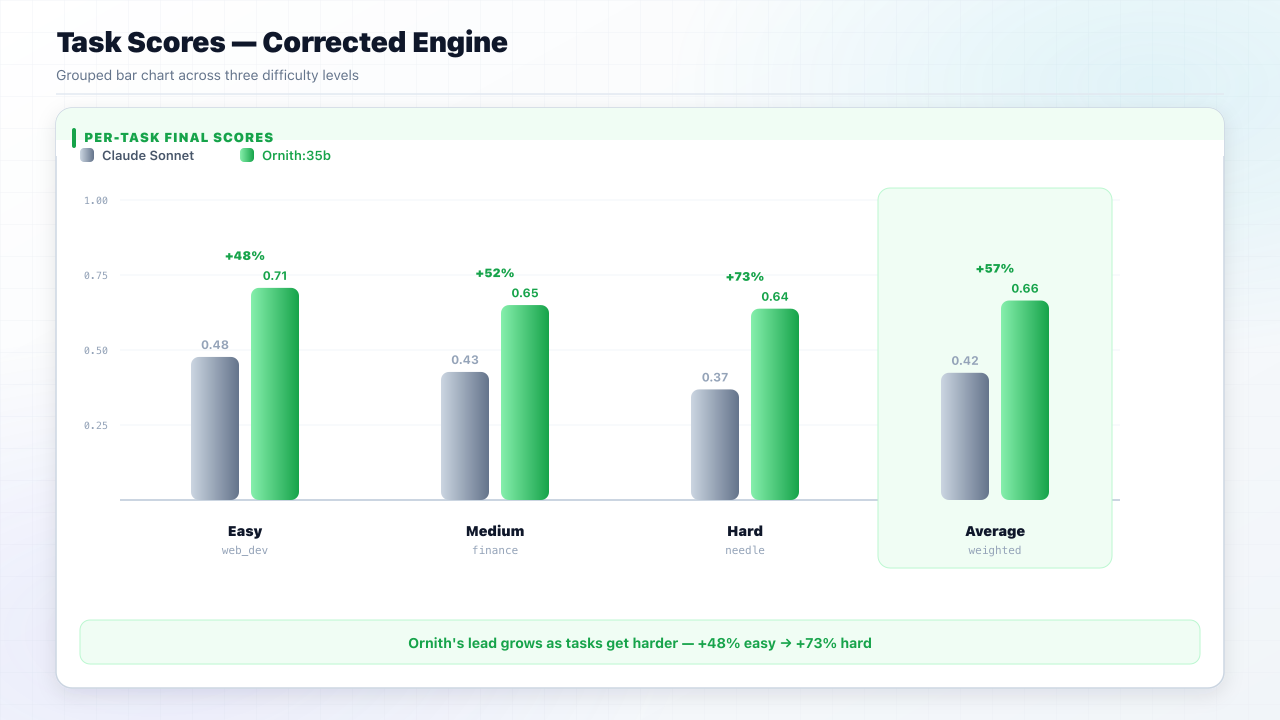
The Full Picture
Ornith's process-score lead widens as tasks get harder (+48% easy → +73% hard), while correctness stays tied.
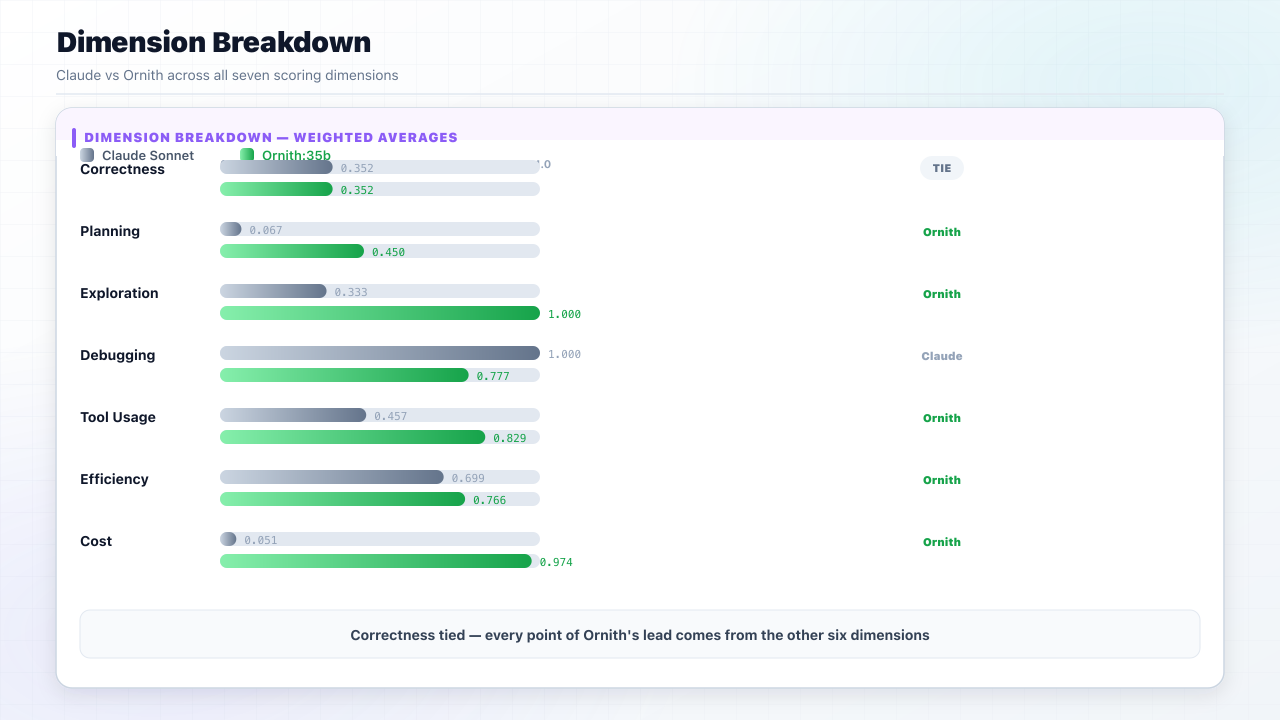
| Dimension | Weight | Claude | Ornith | Ahead |
|---|---|---|---|---|
| Correctness | 0.30 | 0.352 | 0.352 | Tie |
| Planning | 0.10 | 0.067 | 0.450 | Ornith |
| Exploration | 0.10 | 0.333 | 1.000 | Ornith |
| Debugging | 0.10 | 1.000 | 0.777 | Claude |
| Tool Usage | 0.15 | 0.457 | 0.829 | Ornith |
| Efficiency | 0.15 | 0.699 | 0.766 | Ornith |
| Cost | 0.10 | 0.051 | 0.974 | Ornith |
| Final (weighted) | 0.4241 | 0.6649 | Ornith |
Correctness is a dead tie at 0.352. In this benchmark, Ornith's advantage came primarily from the other six dimensions.
Claude's debugging win (1.0) reflects zero failed actions; it rarely attempted operations that could fail. Ornith mixed tools, self-finalized all three tasks, and used roughly a third of the turns.
The Cost Gap
Ornith:35b ran locally at $0. Claude Sonnet cost $2.73 via OpenRouter across all three tasks.
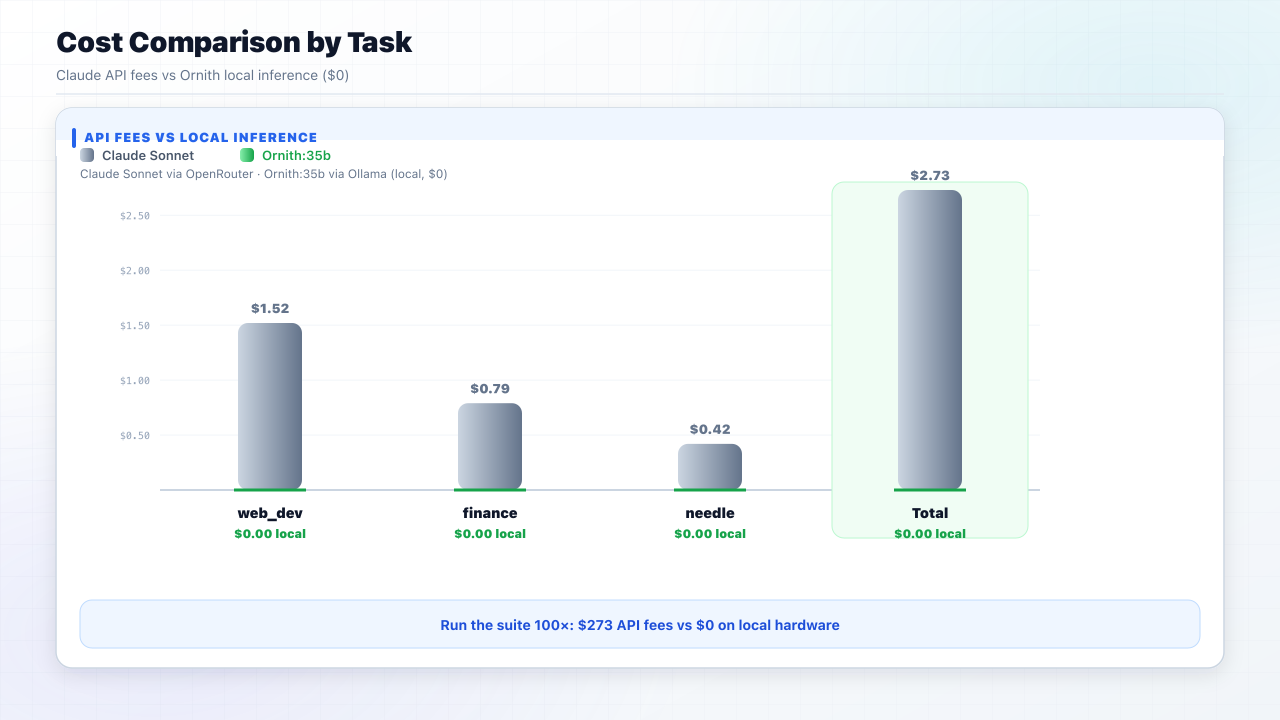
At 100× scale: $273 in API fees vs $0 on local hardware. That's the difference between a one-off eval and a regression check you leave running.
Built to Be Trusted: How We Checked Our Own Scoring
Before publishing, we audited CodeArena itself: framework bugs first, then the scoring engine.
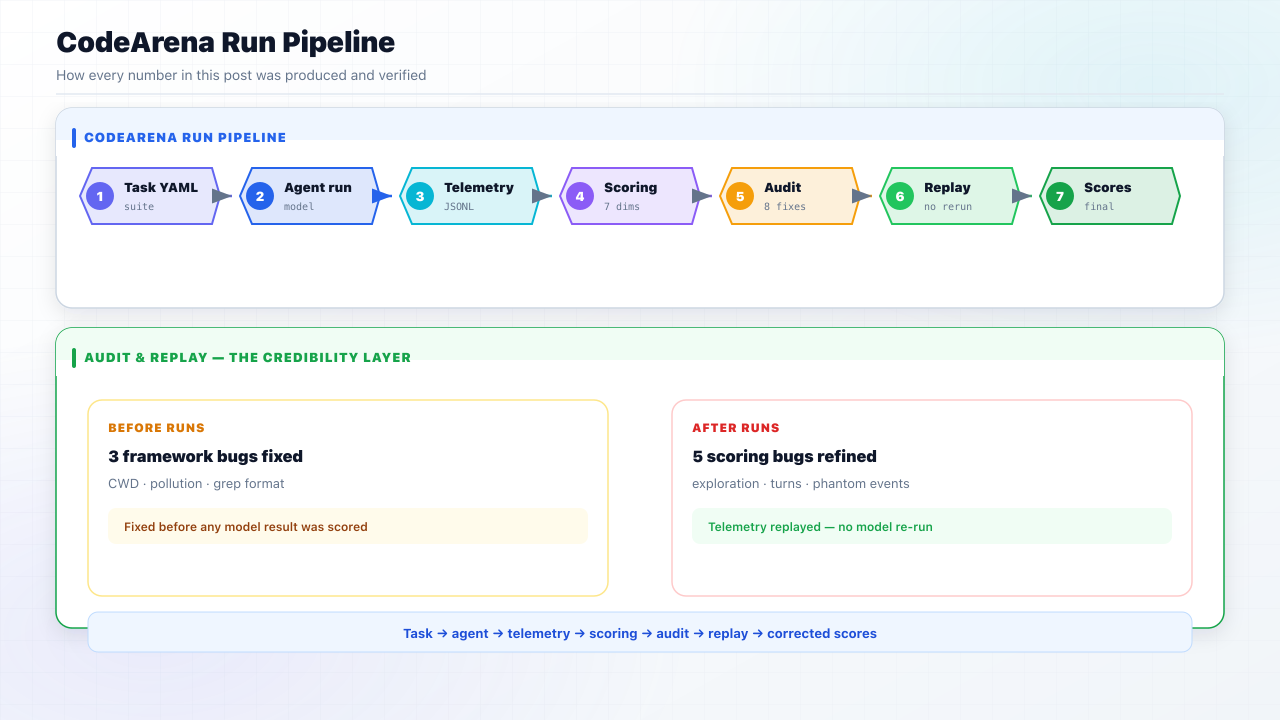
Before runs: three framework issues fixed (wrong test directory, workspace pollution, grep format mismatch). None affected the numbers in this post.
After runs: five scoring refinements. The biggest: exploration credit originally required read_file, missing Claude's terminal-based investigation on the security task. Fixing it raised Claude's exploration score from 0.00 to 0.60 on that task, a correction that helped the model we ranked lower.
All scores were recalculated by replaying recorded telemetry. No model was re-run. Details: scoring changelog, Phase 1 report.
Reading the Numbers Honestly
This is a process comparison, not a capability ceiling test. Neither model built a working multi-file app or found the vulnerability.
On pass/fail alone, this is a tie. The 57% process gap exists because CodeArena weights workflow dimensions beyond correctness.
The cost dimension naturally favors local inference, a deliberate methodology choice, not a hidden tune for Ornith.
Known gaps: finance hidden tests check the CSV both models produced, not the Python app; Claude's security run used a 40-turn cap (task specifies 50; runner default since corrected).
What We Took Away, and Why Developers Should Care
Both models reached nearly identical correctness. The divergence was behavioral: tool diversity, self-termination, and turn efficiency.
Why this matters for production: If you're evaluating AI coding agents for automation pipelines, behavior often matters more than raw pass rate. Agents that terminate correctly, inspect unfamiliar codebases, and recover from mistakes reduce operational cost, even when final correctness is similar. An agent that hits the turn cap every time burns tokens and blocks CI either way.
Pass/fail benchmarks ask whether a model eventually arrived at the answer. CodeArena asks how it got there. In this Claude Sonnet coding vs Ollama case study, that question mattered more than the test count.
Produced with CodeArena v1.0, run on 2026-07-02. Claude Sonnet via OpenRouter; Ornith:35b locally via Ollama (Q4_K_M). Corrected scoring engine; full audit trail in the changelog.
Try NEO in Your IDE
Install the NEO extension to bring an autonomous AI engineer directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor
- MCP: Neo MCP docs