

Autonomous ML Research Loop: Self-Directed Experimentation for ML Research
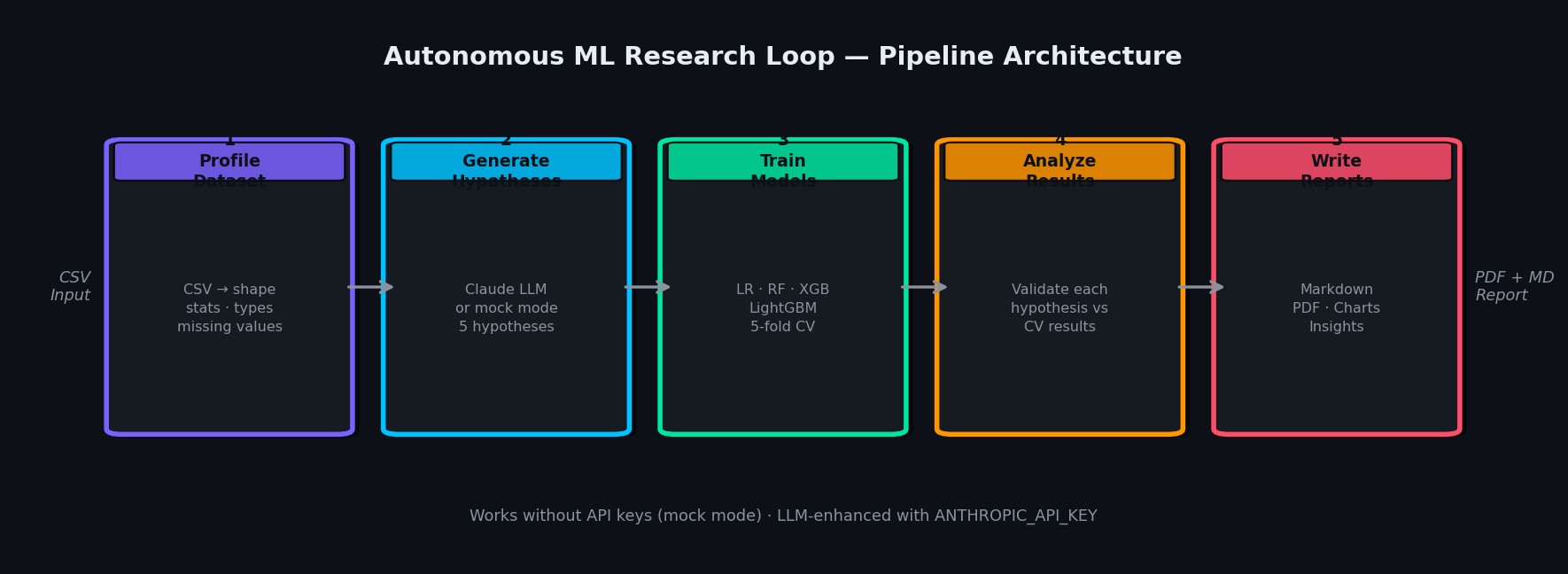
The Problem
ML research is a hypothesis-experiment-analysis loop that researchers run manually, one iteration at a time. Designing the next experiment means reading the last results, updating your mental model, and writing new training configs by hand. The loop is slow, and most of the cognitive work is mechanical.
NEO built Autonomous ML Research Loop to automate that cycle: an LLM-driven planner that reads experiment results, updates a research trajectory, and designs and launches the next experiment — continuously, without a human in the middle.
LLM Planner and Hypothesis Management
Autonomous ML Research Loop begins with a research hypothesis supplied in a YAML file. The hypothesis is a structured object containing a plain-language claim, a set of testable predictions, and an initial experiment configuration:
hypothesis:
claim: "Layer normalization before attention improves convergence speed on small datasets"
predictions:
- "Val loss converges 20% faster with pre-norm vs post-norm at N < 5000 samples"
- "Effect diminishes at N > 50000 samples"
initial_config:
model: transformer_small
dataset: wikitext-2
norm_position: [pre, post]
learning_rate: [1e-4, 3e-4]
dataset_fraction: [0.1, 0.5, 1.0]
The LLM Planner reads the current hypothesis and research trajectory, then produces an experiment configuration: a JSON object specifying model architecture flags, hyperparameter values, dataset splits, and evaluation metrics to collect. The planner is prompted to prioritize configurations that maximize information gain — testing the most uncertain prediction next rather than exhaustively sweeping all parameters.
Executor and Result Parser
The local executor receives the experiment configuration and launches training using a pluggable backend. The default backend is a lightweight custom training loop built on PyTorch that supports the experiment config's model and dataset registry. Configurations are written to a temp directory as Python dataclass files, and the executor spawns a subprocess to run training, capturing stdout and stderr.
After training completes, the result parser reads the generated metrics file and extracts structured fields:
{
"experiment_id": "exp_0042",
"config": {...},
"metrics": {
"final_val_loss": 3.218,
"convergence_epoch": 14,
"train_time_s": 187,
"peak_memory_mb": 2140
},
"status": "completed"
}
Results are appended to a persistent research_log.jsonl file. The parser also runs a prediction checker that evaluates whether each completed experiment confirms or refutes the predictions in the current hypothesis, updating a confidence score per prediction.
Hypothesis Evolution and Research Trajectory
After each experiment result is parsed, the planner re-reads the full research trajectory — the original hypothesis, all completed experiment configs, their results, and the current prediction confidence scores — and performs a hypothesis update step. It either refines the current hypothesis (tightening a prediction, adjusting a threshold, or scoping a claim) or generates a new child hypothesis if a result reveals an unexpected pattern worth investigating.
The research trajectory is a directed graph stored as a JSON file:
Hypothesis H1: pre-norm improves convergence
├─ Exp 001: N=10%, pre vs post → confirmed (p1)
├─ Exp 002: N=50%, pre vs post → confirmed (p1)
├─ Exp 003: N=100%, pre vs post → not confirmed → updates p2
└─ Hypothesis H1.1: effect is architecture-dependent, not dataset-size-dependent
└─ Exp 004: ...
The loop runs until a configurable stopping criterion is met: all predictions reach >0.9 confidence, a maximum number of experiments is exhausted, or no new configurations can be generated that haven't already been run.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build an autonomous ML research loop in Python. Take a structured research hypothesis as YAML input. Use an LLM planner to design experiment configurations, run them via a local PyTorch training executor, parse results into structured metrics, and update a hypothesis trajectory graph. Loop until prediction confidence thresholds are met. Store all experiments in a persistent JSONL research log."
NEO generates the project structure and core implementation. From there you iterate — ask it to add a web dashboard that visualizes the hypothesis trajectory graph, integrate a Weights & Biases logger for experiment tracking, or extend the planner to generate LaTeX-formatted research summaries after the loop completes. Each request builds on what's already there without re-explaining the context.
To run the finished project:
git clone https://github.com/dakshjain-1616/autonomous-ml-research-loop
cd autonomous-ml-research-loop
pip install -r requirements.txt
python loop.py --hypothesis hypothesis.yaml --max-experiments 20
Supply a hypothesis YAML, set a budget on the number of experiments, and the loop runs autonomously — designing, executing, and analyzing experiments until it has enough evidence to confirm or refute each prediction.
NEO built an autonomous ML research loop where an LLM planner continuously designs experiments, a local executor runs them, and a result parser updates a structured hypothesis trajectory — running the full research cycle without human intervention. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor