
Beyond A/B: Building a Multi-Variant LLM Testing Framework with Statistical Rigor
The Problem
Most A/B testing frameworks are built for binary outcomes: click or no-click, convert or bounce. LLM evaluation is fundamentally different. When testing multiple prompt templates, model sizes, and fine-tuned variants simultaneously, running pairwise t-tests inflates your false positive rate — test five variants and you have ten simultaneous tests, each with a 5% chance of a spurious result. Standard tooling simply wasn't built for this.
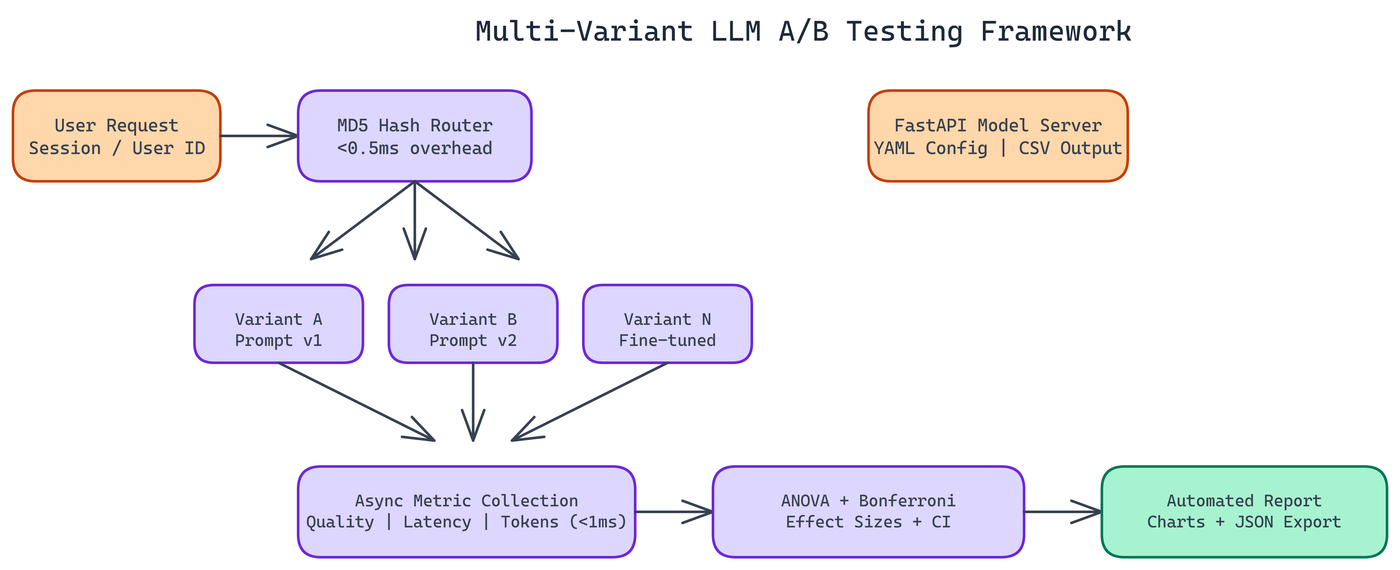
NEO autonomously built a multi-variant testing framework from the ground up, designed specifically for ML systems. It supports N variants simultaneously, uses proper statistical corrections for multiple comparisons, and adds under 0.5ms of routing overhead per request.
How the Framework Works
The system runs four stages in sequence.
Deterministic Routing
Incoming requests get assigned to variants using MD5-based hashing on a user or session identifier. This is deterministic. The same user always hits the same variant. That matters because it eliminates the noise you get when the same user experiences multiple variants inconsistently.
Routing overhead is under 0.5ms. It is not a bottleneck.
Async Metric Collection
Metric logging is fully asynchronous. The system uses a queue-based design so logging never blocks the request path. Total logging overhead stays under 1ms per request. In high-throughput production environments, non-blocking collection is not optional.
The system tracks response quality scores, latency, token usage, and any custom metrics you define per experiment.
Statistical Analysis
This is where the framework earns its keep. For continuous metrics across N variants, the framework runs one-way ANOVA first. If that test shows a statistically significant difference somewhere in the group, it moves to pairwise comparisons with Bonferroni correction.
Bonferroni correction adjusts the significance threshold for each individual test based on the total number of comparisons being made. It keeps the family-wise error rate under control. For categorical outcomes, Chi-Square tests with the same correction are applied.
Every result comes with confidence intervals and effect sizes, not just p-values. A statistically significant result with a tiny effect size might not be worth shipping.
Automated Reporting
The output is a full report with publication-ready visualizations, effect size tables, and JSON export for downstream integration. Results are ready to share with a team or feed into another system without manual processing.
Configuration and Integration
The framework is YAML-configured. You define your variants, traffic splits, metrics to track, and experiment duration. Results accumulate in CSV format for immediate analysis.
There is a FastAPI endpoint for model serving, so you can integrate this directly into an existing ML serving stack. Teams running online experiments do not need a separate infrastructure layer.
Real Use Cases
The most common use case is prompt template comparison. You have a system prompt you wrote six months ago and a new version. You want to know if the new one actually improves response quality across a real distribution of user queries, not just the five examples you tested manually.
Other uses: comparing model sizes (does the 70B variant meaningfully outperform the 13B on your specific task?), evaluating fine-tuned vs. base models, testing different retrieval strategies in a RAG system.
The framework handles all of these. As long as you can define a metric, you can test it.
What Rigorous Testing Actually Buys You
The alternative to proper statistical testing is intuition-driven decisions. Someone looks at a sample of 20 responses, decides one prompt "feels better," and ships it. That works sometimes and fails silently much of the time.
With this framework, you get confidence intervals that tell you the true effect size range. You get correction for multiple comparisons so you are not chasing noise. You get effect sizes so you know whether a statistically significant improvement is actually large enough to matter in practice.
That is the difference between shipping a hunch and shipping a measured improvement.
How to Build This with NEO
Open NEO in VS Code or Cursor and describe what you want to build. A good starting prompt for this project:
"Build a multi-variant A/B testing framework for LLMs in Python. Support N variants simultaneously with MD5-based deterministic routing on user IDs, async queue-based metric logging under 1ms, one-way ANOVA with Bonferroni correction for multiple comparisons, effect size reporting, and a FastAPI endpoint for model serving. Export results as CSV and generate publication-ready visualizations."
NEO generates the project structure and core implementation from that. From there you iterate — ask it to add Chi-Square testing for categorical outcomes, build out the YAML configuration schema for defining experiment variants and traffic splits, or extend the report generator with confidence interval tables. Each request builds on what's already there without re-explaining the context.
To run the finished project:
git clone https://github.com/dakshjain-1616/AB-testing-tool.git
cd AB-testing-tool
pip install -r requirements.txt
python3 run_full_pipeline.py
Results land in results/ — open the generated charts and summary tables to see flip rates, effect sizes, and Bonferroni-corrected p-values across all variants. Start the FastAPI server with python3 src/serving.py to route live requests.
NEO built a multi-variant LLM testing framework where rigorous statistical evaluation—ANOVA, Bonferroni correction, effect sizes—is a first-class concern, not an afterthought. See what else NEO ships at heyneo.com.
Try NEO in Your IDE
Install the NEO extension to bring AI-powered development directly into your workflow:
- VS Code: NEO in VS Code
- Cursor: Install NEO for Cursor